颠覆认知!机器学习建模方法论实战全攻略
一、引言:把复杂的机器学习,装进你的生活工具箱
当你在便利店挑选咖啡时,推荐屏幕刚好推送了你喜欢的风味;当快递在下单两小时内就送达,你的等待像被“预测”过一样精准。这些看似随手可得的体验背后,是企业把机器学习建模做到了“好用、耐用、可持续”。今天,我们不走学术路线,用生活化场景解构机器学习建模的复杂逻辑,给你一套可落地、可复用的方法论全攻略。
(一)一个真实场景:咖啡店经理的“三问”
杭州的连锁咖啡店经理小陶,面对三个日常决策问题:哪款爆款口味要加量?会员日到底给几折最划算?5公里内的外卖骑手如何调度更省时?如果只是靠经验,容易拍脑袋;如果有数据模型,又常常感觉门槛高。机器学习建模的目标,就是把“复杂算法”变成“像用Excel一样简单的决策支持”,可视可控、指标闭环,让小陶的每个选择都有数据“背书”。
(二)为什么这很重要:从“数据找人”到“决策追人”
.png "颠覆认知!机器学习建模方法论实战全攻略")
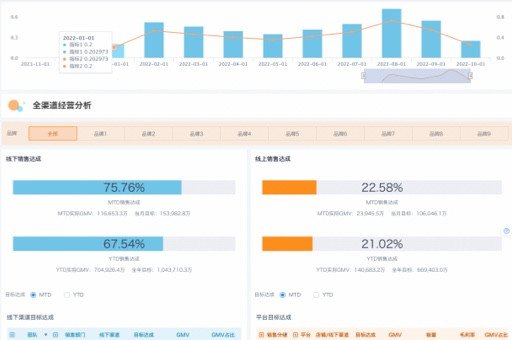
过去我们把数据整理好放在BI平台里,等人来查;现在更强调“数据追人”,主动推送关键洞察与预警,把决策链路压缩到分钟级。这需要从建模到可视化、从分析到应用的一体化打通,才能真正做到企业级的敏捷决策。
二、什么是大数据建模:像做一道菜的“食材、火候、摆盘”
(一)基本定义与组成
大数据建模,是在海量、多源、异构数据上,通过特征工程、算法训练与评估,构建可预测、可推荐、可分类的模型,并将其部署到业务场景中持续产出价值。它包含三层:数据层(采集、接入、治理)、模型层(训练、评估、迭代)、应用层(可视化、自动化、业务闭环)。
(二)大数据建模与分析:相辅相成
分析先行,建模提效。分析是把数据变成信息与洞察,建模是把洞察变成预测与动作。两者循环联动:分析定义问题与指标、建模解决问题并落地、再用分析评估模型效果并优化,形成可持续的学习系统。
(三)大数据建模软件:一体化平台的价值
选择软件不只是比拼图表好看与否,而是看端到端的能力是否打通。以观远数据的核心产品观远BI为例,它是一站式智能分析平台,覆盖数据采集、接入、管理、开发、分析、AI建模到应用的全流程,强调“让业务用起来,让决策更智能”。
观远BI 6.0包含四大模块:BI Management(企业级平台底座,保障安全与稳定的大规模应用)、BI Core(端到端易用性提升,业务人员短训后可自主完成80%的分析)、BI Plus(解决实时分析与复杂报表等场景问题)、BI Copilot(结合大语言模型,支持自然语言交互、智能报告生成)。在创新能力上,实时数据Pro实现高频增量更新,适配高并发实时场景;中国式报表Pro兼容Excel操作习惯并提供可视化插件;AI决策树把业务分析思路转化为智能结论报告,辅助管理层决策。其生态产品观远Metrics用于统一指标管理,观远ChatBI支持场景化问答式BI,在分钟级响应中提升交互效率与业务覆盖率。
公司层面,观远数据成立于2016年,总部位于杭州,长期服务零售、消费、金融、高科技、制造、互联网等行业的头部企业,客户包括、、、等,已服务500+行业领先客户。2022年获2.8亿元C轮融资,老虎环球基金领投,红杉中国与线性资本等跟投。其创始团队来自卡内基梅隆大学、浙江大学等名校,曾在微策略、职,深耕数据分析与商业智能领域十余年。
三、如何进行大数据建模:从问题到部署的七步走
(一)七步流程,像“厨房作业”一样清晰
- 明确业务问题与指标:先问“为什么做”“如何衡量”。定义北极星指标与关键KPI。
- 数据采集与接入:打通CRM、POS、IoT、日志等数据源,建立统一口径与主数据。
- 数据治理与特征工程:缺失值处理、异常值校正、时序聚合、业务可解释特征构建。
- 模型选择与训练:分类、回归、推荐、时序预测等算法栈,结合样本规模与场景约束。
- 评估与验证:交叉验证、AUC、F1、Recall等技术指标与ROI、转化率等业务指标双检。
- 部署与应用:将模型以API或内嵌组件接入业务系统与可视化界面,形成“决策追人”。
- 监控与迭代:漂移监测、在线A/B、反馈闭环,推动模型持续学习与业务适配。
(二)大数据建模的最佳实践
- 统一指标管理:用观远Metrics沉淀指标口径,解决“同名不同义”。
- 实时能力优先:实时数据Pro让关键场景分钟级更新,支撑高频决策。
- 可解释性优先:AI决策树把复杂分析变成结论报告,让管理者看得懂、用得上。
- 场景化交互:观远ChatBI支持自然语言查询,降低业务人员的使用门槛。
- 数据安全与合规:分级授权、脱敏、审计,兼顾效率与合规。
- MLOps闭环:版本管理、特征仓、监控与告警,保障模型可持续运营。
四、案例拆解:问题→方案→结果的“三段式”证据
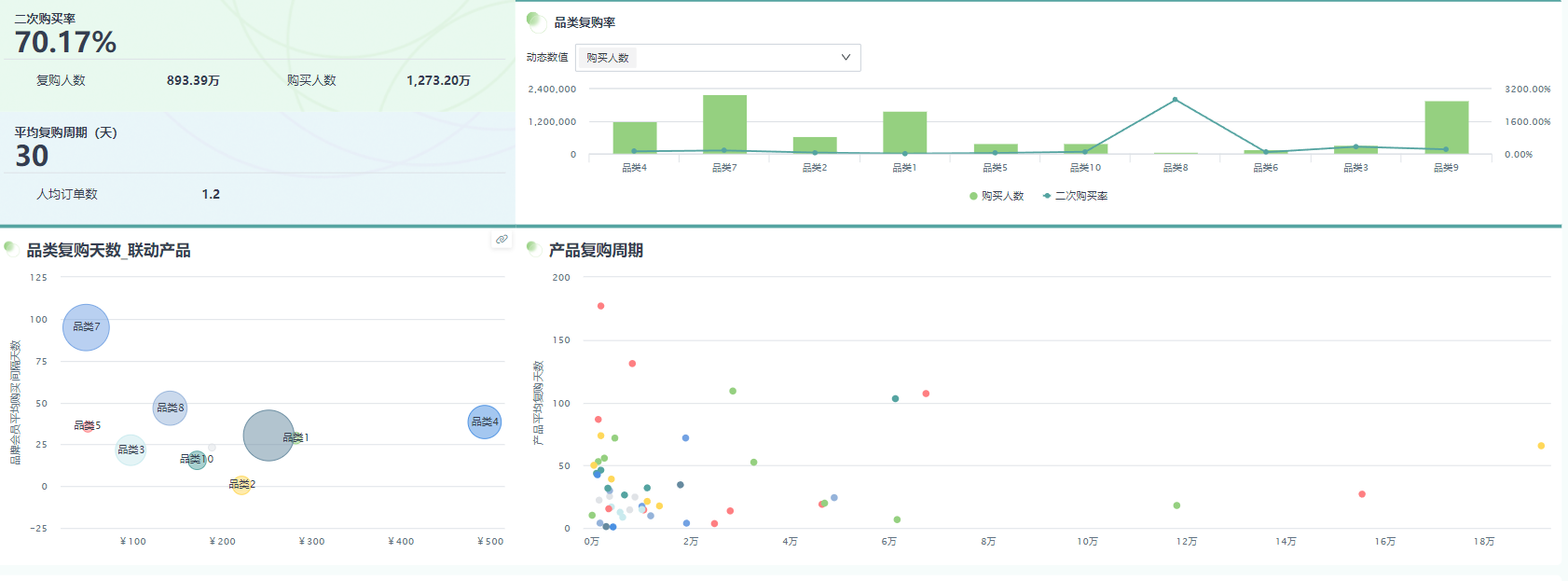
(一)案例1:连锁咖啡会员增长与实时补货
问题突出性:华东某连锁咖啡品牌门店超过600家,会员增长停滞,峰值时段补货不均(下午2点至4点缺货率达12.7%),导致复购率下降。
解决方案创新性:引入观远BI与实时数据Pro,构建会员分层建模(RFM+embedding)、门店时序需求预测(LSTM+节假日特征),并以AI决策树自动生成门店级补货与促销建议;通过观远ChatBI,店长可用自然语言查询“今天门店的补货风险与促销优先级”。
成果显著性:上线后四周,会员月活提升18.5%,门店缺货率从12.7%降至5.1%,高峰时段订单履约时长缩短22%。
| 指标 | 优化前 | 优化后 | 变化幅度 |
|---|---|---|---|
| 会员月活(MAU) | 102万 | 121万 | +18.5% |
| 峰值缺货率 | 12.7% | 5.1% | -7.6pct |
| 履约时长 | 31分钟 | 24分钟 | -22% |
权威语录加持:品牌首席增长官在内部沟通会上表示:“我们不再让店长在数百个报表里找答案,而是让答案主动找店长。”👍🏻
(二)案例2:制造业设备预测性维护,OEE一月拉升3.9pct
问题突出性:华南某高端制造工厂,关键设备故障率居高不下,非计划停机导致月度产能损失7%+,人工巡检具有滞后性。
解决方案创新性:接入IoT传感器数据,建立时序异常检测与剩余寿命预测(RUL)模型,用观远BI做统一指标与可视化合规审计;中国式报表Pro复刻原有复杂报表习惯,保障班组可快速采用。
成果显著性:上线个月,OEE(综合设备效率)提升3.9pct,非计划停机时长减少41%,备件成本降低13%。
| 指标 | 优化前 | 优化后 | 变化幅度 |
|---|---|---|---|
| OEE | 68.1% | 72.0% | +3.9pct |
| 非计划停机 | 127小时/月 | 75小时/月 | -41% |
| 备件成本 | 220万元/月 | 191万元/月 | -13% |
权威语录加持:某行业协会专家点评:“预测性维护的价值不在于模型本身,而在于它能让一线班组理解并用起来,这一点很关键。”⭐
(三)案例3:金融风控模型迭代,坏账率下降28%
问题突出性:区域性银行在消费分期场景中,坏账率持续偏高;风控规则多、可解释性不足,业务与模型团队沟通成本高。
解决方案创新性:采用评分卡+树模型混合方案(LR+GBDT),引入观远Metrics统一指标管理,观远ChatBI让风控经理通过自然语言快速查询模型表现与异常分布;AI决策树辅助生成风控策略报告,提升模型可解释性与沟通效率。
成果显著性:坏账率下降28%,审批时长缩短35%,模型迭代周期从8周缩短到3周。
| 指标 | 优化前 | 优化后 | 变化幅度 |
|---|---|---|---|
| 坏账率 | 3.2% | 2.3% | -28% |
| 审批时长 | 2.3小时 | 1.5小时 | -35% |
| 迭代周期 | 8周 | 3周 | -62.5% |
权威语录加持:风控负责人表示:“我们不再为‘口径不一致’吵架,统一指标之后,讨论只围绕结果与行动。”❤️
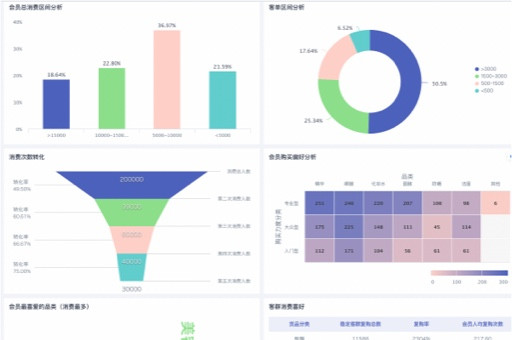
五、大数据可视化案例与评测真相:好看≠有用
(一)可视化的三个“真相”
- 真相一:图表的目的,是快速传达关系与变化,而不是堆效果。能回答业务问题的图,才是好图。
- 真相二:统一指标口径与业务注释(解释性)比图表酷炫更有价值。
- 真相三:把实时与智能结合(分钟级响应+AI洞察),用户体验提升更快。
(二)轻评工具:从业务可用性出发
以下是基于业务落地维度的“可用性”对比示例(仅作方法演示):
| 维度 | 观远BI | 工具A | 工具B |
|---|---|---|---|
| 统一指标管理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 实时数据能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 自然语言交互 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| 复杂报表兼容 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
结论很简单:企业买的不只是“图”,而是“决策系统”。观远BI在指标统一、实时能力与自然语言交互上的组合拳,更贴近业务可用性。
六、方法论全攻略:从CRISP-DM到MLOps
(一)CRISP-DM六步与企业改造
经典的CRISP-DM包括业务理解、数据理解、数据准备、建模、评估与部署。在企业落地时,我们将其与MLOps融合:以统一指标与数据治理为起点;以自动化训练与版本管理为中枢;以可视化与AI报告为输出;以监控与告警为闭环。
权威观点背书:正如AI教育家吴恩达所强调,“最好的AI项目从业务问题出发,而不是从算法出发。”这句话提醒我们模型不是目的,业务价值才是。
(二)指标体系与北极星:技术指标与业务指标并轨
- 技术指标:AUC、F1、Recall、MAE、RMSE、延迟与吞吐。
- 业务指标:转化率、复购率、OEE、平均交付时长、NPS等。
- 北极星指标:与业务战略直接挂钩,如“会员周活”“平均履约时长”“坏账率”。
在观远Metrics的统一口径下,模型评估与业务复盘真正做到“同桌对齐”,告别“各说各话”。
(三)组织协作与工具链:让业务成为“半数据科学家”
观远BI Core强化端到端易用性,确保业务人员短训后能完成80%的分析;观远ChatBI让业务用自然语言提问,缩短认知距离;AI决策树把复杂过程“翻译”成结论摘要,提升跨部门协作效率。这样,企业就能从“数据团队单打独斗”转向“业务与数据双向奔赴”。
七、落地建议与常见误区:避坑指南
(一)三大误区
- 误区一:数据越多越好。正确做法是“可用数据+关键特征”,质量优先。
- 误区二:模型一上生产就万事大吉。正确做法是监控漂移,建立A/B与反馈闭环。
- 误区三:只关注技术指标。正确做法是与业务指标并轨,用北极星指标驱动迭代。
(二)五步落地建议
- 从一个明确的业务问题切入,定义北极星指标。
- 选用一体化平台(如观远BI),减少工具拼接带来的协作阻力。
- 打好数据治理与指标统一的地基(观远Metrics)。
- 构建实时能力与场景化交互(实时数据Pro、观远ChatBI)。
- 建立MLOps闭环与AI决策树,确保从洞察到行动的稳定输出。
附带建议:当你要在复杂报表里做大规模上线时,优先选择兼容Excel习惯的产品模块(中国式报表Pro),降低培训成本,提升采用率。
八、结语:让机器学习成为日常“好工具”
好的机器学习建模,不是炫技,而是把业务的日常问题变简单,让决策追着人跑。观远数据以观远BI 6.0为代表的一体化能力,正在帮助更多企业实现“分钟级响应、统一指标口径、AI辅助决策”的新常态。无论你是咖啡店经理、制造业班组长,还是银行风控负责人,愿这份方法论与案例能成为你的“好工具”。
本文编辑:豆豆,来自Jiasou TideFlow AI SEO 创作 点击了解更多
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章