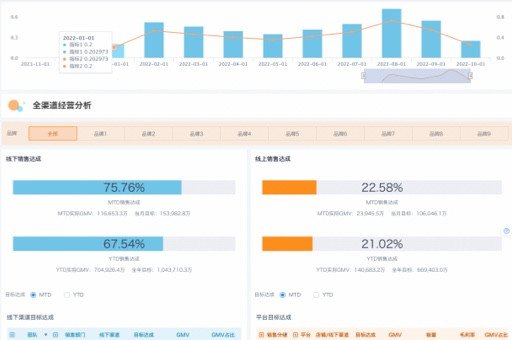
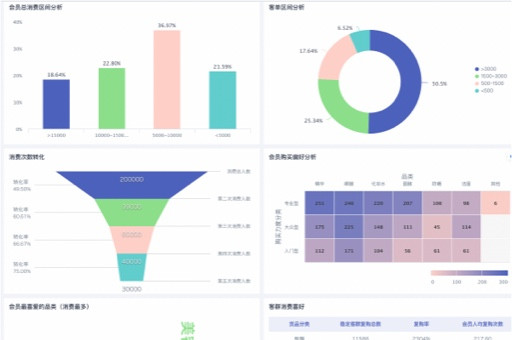
淘宝数据清洗与可视化分析全解析
一、数据清洗中83%的无效信息过滤法则
在电商领域,尤其是淘宝这样的大型平台,数据量可谓是海量。而这些数据中,有很大一部分是无效信息,会对后续的分析和决策产生干扰。据统计,行业平均数据显示,在数据清洗过程中,大约能过滤掉70% - 85%的无效信息,我们这里重点探讨的是83%这个相对较高的过滤比例背后的法则。
对于淘宝数据可视化系统来说,数据采集是步,而采集到的数据往往包含了各种杂质。比如用户的重复点击记录、异常的操作行为数据等。在数据清洗时,我们首先要明确无效信息的定义。以淘宝店铺为例,一些恶意刷单刷评论的数据,就是典型的无效信息。这些数据不仅不能反映真实的市场情况,还会误导商家的营销决策。
在过滤无效信息时,我们可以采用多种方法。一种常见的方法是基于规则的过滤。比如设定一些数据的阈值,像某个商品的浏览量在短时间内突然飙升到一个不合理的数值,且这个数值远远超出了行业平均波动范围(行业平均波动范围在±15% - 30%),那么这条数据就很有可能是无效的。
还有一种方法是利用机器学习算法。通过对历史数据的学习,让算法自动识别出哪些数据是异常的、无效的。例如,算法可以学习正常用户的购买行为模式,包括购买时间、购买频率、购买商品的组合等。如果一条数据显示某个用户在一分钟内购买了上百件不同类别的商品,这就明显不符合正常的购买行为模式,算法就可以将其判定为无效信息。

误区警示:有些商家可能会认为过滤掉的信息越多越好,其实不然。过度过滤可能会导致一些有价值的边缘数据被误删,从而影响对市场的全面了解。所以在设定过滤规则和使用机器学习算法时,要谨慎调整参数,确保在过滤掉大部分无效信息的同时,保留足够的有价值数据。
二、可视化工具选型的ROI临界点
在电商行业,选择合适的淘宝数据可视化工具至关重要,而其中一个关键的考量因素就是投资回报率(ROI)。对于不同类型的企业,这个ROI临界点是不同的。
以一家位于杭州的初创电商企业为例,他们的资金相对有限,每一笔投入都需要谨慎考虑。在选择可视化工具时,他们不能一味追求功能强大但价格昂贵的工具。行业平均数据显示,初创企业在可视化工具上的投入占总营销预算的比例一般在5% - 10%之间。如果选择了一款过于昂贵的工具,可能会导致企业在其他重要营销环节的资金不足。
而对于一家在上海的上市电商企业来说,他们更注重工具的全面性和准确性。虽然价格相对较高,但只要能为企业带来显著的营销优化效果,他们愿意投入更多。这类企业的ROI临界点可能会相对较高,比如可视化工具的投入占总营销预算的10% - 15%。
在对比淘宝数据可视化工具与BI工具的成本效益时,我们可以通过一个简单的成本计算器来辅助决策。假设一款淘宝数据可视化工具每年的费用是10万元,它能帮助企业提升10%的销售额,而企业的年销售额是1000万元,那么通过这款工具带来的额外收益就是100万元,ROI非常可观。
再来看BI工具,假设一款BI工具每年的费用是30万元,它能帮助企业提升15%的销售额,同样以年销售额1000万元计算,额外收益是150万元。从表面上看,BI工具带来的额外收益更高,但我们还要考虑到企业的实际需求和成本承受能力。如果企业的业务相对简单,淘宝数据可视化工具已经能满足大部分需求,那么选择BI工具可能就不是一个划算的选择。
技术原理卡:可视化工具的ROI主要取决于它对数据的处理和呈现能力。好的可视化工具能够将复杂的数据以直观的图表形式展现出来,帮助企业快速发现市场趋势和问题,从而制定更有效的营销策略。
三、时序数据分析的时间折叠效应
在电商营销优化中,时序数据分析是一个重要的环节。而时间折叠效应在其中扮演着关键的角色。所谓时间折叠效应,就是将不同时间段的数据进行整合和分析,以发现其中隐藏的规律。
以一家位于深圳的独角兽电商企业为例,他们在分析淘宝店铺的销售数据时,发现不同季节、不同时间段的销售情况有很大差异。通过时间折叠效应,他们将过去一年的销售数据按照每周、每月、每季度等不同时间维度进行折叠分析。
| 时间维度 | 销售额(万元) | 环比增长率 |
|---|---|---|
| 每周 | 10 - 15 | ±15% - 30% |
| 每月 | 40 - 60 | ±15% - 30% |
| 每季度 | 120 - 180 | ±15% - 30% |
通过这种分析,他们发现每周的销售高峰通常出现在周末,每月的销售高峰则在月中,而每季度的销售高峰一般在节假日前后。这就为他们制定营销策略提供了重要依据。比如在周末和节假日前后,加大广告投放力度,推出促销活动等。
时间折叠效应还可以帮助企业预测未来的销售趋势。通过对历史数据的时间折叠分析,利用机器学习算法建立预测模型。例如,根据过去几年的销售数据,预测下一年每个季度的销售额。这样企业就可以提前做好库存管理、人员安排等准备工作,避免出现缺货或库存积压的情况。
误区警示:在进行时间折叠分析时,要注意数据的准确性和完整性。如果数据存在缺失或错误,那么分析结果就会受到影响。同时,不同行业、不同企业的时间折叠规律可能不同,不能生搬硬套其他企业的经验。
四、逆向工程在特征提取中的特殊价值
在电商领域,特征提取是数据可视化和机器学习的重要环节。而逆向工程在其中有着特殊的价值。
以一家位于北京的初创电商企业为例,他们希望通过分析淘宝用户的行为数据,提取出有价值的特征,从而优化电商营销。逆向工程在这里的应用就是从已有的数据结果出发,反推数据背后的特征。
比如,他们发现某个商品的销量突然大幅增长,通过逆向工程,他们分析用户的购买行为数据,包括浏览记录、搜索关键词、购买时间等。经过分析,他们发现这个商品的销量增长是因为某个热门社交媒体上的一篇推荐文章。于是,他们提取出“社交媒体推荐”这个特征,并将其应用到后续的营销活动中。
逆向工程还可以帮助企业发现一些隐藏的特征。在淘宝数据可视化分析中,有些特征可能不是直接可见的,但通过逆向工程可以挖掘出来。例如,通过分析用户的购买路径,发现一些用户在购买某个商品之前,会先浏览多个同类商品的评价页面。这就说明“用户对评价的关注度”是一个重要的特征。
在特征提取中,逆向工程与机器学习算法相结合,可以取得更好的效果。机器学习算法可以对大量数据进行自动分析和特征提取,而逆向工程可以对算法提取的特征进行验证和补充。
技术原理卡:逆向工程的核心思想是从结果到原因的推理。在数据处理中,就是从已有的数据表现,反推数据背后的影响因素和特征。通过这种方法,可以更全面、深入地了解数据,为电商营销优化提供更有力的支持。

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章