
观点 | 如何从零搭建企业级大数据分析平台

《观点》栏目是由观远数据倾力打造的一档技术类干货分享专栏,所有内容均来源于观远数据内部员工,旨在为数据分析行业输出指导性的知识体系。
5月28日,观远数据联合创始人兼首席架构师吴宝琪做客【51CTO大咖来了】直播间,在线分享《如何从0搭建企业级大数据分析平台》。

讲师简介:
观远数据联合创始人兼首席架构师
毕业于南开大学计算机学士&硕士
曾就职于微策略、p>
Apache DolphinScheduler PPMC
Netflix Polynote contributor
演讲提纲:
企业什么时候需要BI
BI在技术能力上包含什么
BI在应用和发展中有哪些机遇和挑战
BI如何衍生数据生态
未来,BI有哪些发展趋势
01.
企业什么时候需要BI
BI(Business Intelligence),中文为:商业智能。是利用软件或服务来把遍布于企业各处的数据转化为可行动的洞察,从而来影响企业的战略和战术决策。
BI进入中国市场已经有20余年,而到目前,并不是所有企业都配备了BI系统。有些公司体量较小,需要处理的数据量只有不到10万行,一套Excel就可以解决。
而随着很多公司规模越来越大,逐步健全了ERP、POS、CRM、OA等IT系统,沉淀了海量的数据资源,如果还是从单一系统来看数据,对于最高决策层来说,就很难全局了解整个公司的整体运营情况,这时,企业对BI的需求就应运而生。
BI不仅能给公司提供一个权限分明的一站式大数据分析平台,解决数据融合的问题,还可以弥补Excel、报表等事后分析、静态报告的弊端,提供实时、动态交互的分析能力。以观远数据为代表的新一代BI平台,还可以在此之外提供可视化自助分析、十亿行数据秒级响应、一键AI预测等超前的数据分析能力。

总结来说,当企业数据量达到几十万行,业务量正在急速增加,而传统的分析工具已经很明显地跟不上内部业务发展速度,严重影响决策效率和准确度,或者公司已经有了明确的IT项目规划,都可以考虑使用BI系统。
02.
BI在技术能力上包含什么
BI是一个复杂的系统,涉及到技术的方方面面,而对于企业要实现的功能来说,主要可以总结为以下六点:
数据可视化
数据分析
数据集成
内容分发
企业集成
部署方式
1、数据可视化
对于企业最为关心的可视化模块,可以通过以下几种开源技术进行实现:ECharts、D3、Vega & Vega-Lite。
(观远数据数据可视化图片)
ECharts是目前国内最流行的开源可视化图表库,起源自百度,目前在Apache孵化器中孵化。ECharts提供了使用“JSON”来开发定制的配置方式,带有很多丰富的可视化图形,很适合与起步阶段的企业。(详细操作可参考:技术人员眼中的BI之可视化 —— 实干家:ECharts)
D3,全名是:Data-Driven Documents。D3的特点首先是表达能力非常强大,其次是非常底层,如果类比编程语言的话, D3可以算是C语言,SVG是汇编语言。(详细操作可参考:技术人员眼中的BI之可视化 ——艺术家:D3)
Vega 和 Vega-Lite都诞生于美国华盛顿大学交互数据实验室(Interactive Data Lab)。相比于同是受“图形语法”启发的D3,Vega对于非常多的通用可视化提供了便利的支持,并且也仍有一定的定制化能力。而 Vega-Lite 则是基于Vega,对于各种常用统计图形提供了更简单直接的支持。(详细操作可参考:技术人员眼中的BI之可视化 —— 标准家:Vega & Vega-Lite)
对于使用ECharts来说,首先会去看自己想要做什么样的图形,再去找例子,然后看怎样把数据转换成图形,是一种从图形到数据的过程。而对于Vega-Lite来说,首先是看自己到底有哪些数据,然后去看从哪些维度进行分析,最终的可视化图形就自然来了,所以它是一个从数据到图形的过程。这两者看着类似,但其实理念是不一样的。而对于BI来说,基础是数据,然后再去看要怎么分析,这样才能抓住重点。
2、数据分析
有了Vega-Lite和Voyager就可以产生BI?如果将这两者进行组合来代替BI,很快企业又会遇到新的瓶颈。例如,Vega-Lite默认是把所有的数据都加载到前端JS中进行处理,一旦数据量已经大到了几千万上亿行,就很难处理,需要有一个强大的后端去支持,这个就是数据分析过程。
比如说企业一些主要数据,默认为他来自于一些关系型数据库,所以,最简单的处理方法就是,先去看下Vega-Lite产生的JSON有哪些数据维度,做了哪些数据转换,然后把它转化成关系型数据库所需要的SQL形式去直接查询数据库,这样就解决了数据直连中数据量过大的问题。
除了支持关系型数据库,在BI系统中,可以通过把CSV和Excel导入到关系型数据库中,通过查询关系型数据库,处理本地的数据文件。对于企业拥有多种数据库类型,为了解决跨库查询的难题,可以将不同数据库的数据导入到某个关系型数据库中作为中央库来解决,或者使用一些外部表来关联数据,也可以起到数据融合的作用。
当企业的数据量越来越大,一台关系型数据库无法承载时,则可以使用大数据或分布式处理的方式。例如观远数据目前依托Apache Spark数据处理引擎,再结合Kubernetes来管理,就可以形成一个分布式、集群化的操作系统汇总所有的数据,做到分布式处理。
3、数据集成
数据是BI的基础,而在企业内部,数据源不会只来源于一个途径,可以是关系型数据库、CSV、Excel、Web Services等。
观远数据目前可以支持20多种数据库对接。对于CSV或者Excel,可以把它导入到中央存储库中,CSV可以用Apache Commons-CSV去解析内容,Excel就可以用Apache POI来解析。对于关系型数据库,可以直接用JDBC或ODBC接口来直接查询,或者把它们也导入到中央数据库中。
而对于其他类型,比如Web Services、业务系统、HBase、ElasticSearch等,建议可以把一些基础的操作定义为插件的API,并提供一些SDK来辅助业务人员去编写插件,这样就接入系统中各种各样的数据,真正做到融合所有数据。
4、数据分发
数据分发可以总结为数据可视化结果展现给用户端的能力,比如我们常见的用Excel表格做日报周报,或者静态的PPT分析报告等。
观远数据目前提供数据大屏、移动BI轻应用等多种应用形式,并且支持数据预警、邮件订阅等功能,当数据达到危险阀值时也能一键触发给对应负责人。
5、企业集成
BI是企业决策的一个中枢系统,但如果不能很好地融入到企业常规办公系统中,也会给使用者带来困扰。而达到这个目的,首要考虑的是如何把他的账号体系和核心办公系统绑定在一起。
这个时候就可以使用Keycloak,它是集中身份认证和访问控制中心,提供了单点登陆SSO、用户组、角色管理、微服务授权等多功能。尤其当企业的应用平台较多时,如果说每一个系统都要求实现一套自己的帐号管理,就会带来一些重复的开发成本和复杂的使用体验。另外,借助Keycloak这种集中身份认证,也可以把微服务等也纳入到权限控制体系中,真正做到单点登录。
6、部署方式
不同的企业用户对于BI部署方式的选择不一样,选择之后所做的一系列动作也会存在很大差异。如果是部署在公有云上,就要充分应用公有云的功能,例如公有云所提供的托管服务,可以用它托管数据存储、数据监控、日志等。
利用公有云的优点是:可以借助云服务商大量现成的功能,快速开发自己的系统。另外,云服务商是比较稳定的,也有很多专业的运维人员帮企业做运维,这样就可以节约成本。但同时也要考虑一点,就是云服务商是按照阶梯收费的,随着企业数据量越来越大,云服务上的消费也会越来越高,而因为之前在云服务商上已经绑定了很多专有服务,所以就很难再迁移到其他服务商上。
如果说企业的业务既有本地化部署又有公有云,则可以采用Kubernetes。如果是公有云,企业可以使用托管的Kubernetes集群。而对于私有化就会复杂一点,需要自己去管理和安装Kubernetes,这个是比较有挑战的,还要考虑到Kubernetes的高可用性。当然,如果是节点比较少的时候,建议可以使用简化版的Kubernetes —— K3S就可以大大简化安装过程。
03.
BI在应用和发展中遇到的机遇和挑战
不管是数据可视化、数据分析、数据集成、内容分发、企业应用还是部署方式,BI功能实现的每个环节都充满了挑战。主要集中在以下几点:
如何去融合和管理BI所有的功能点。尤其是当企业的BI平台已经有上百个功能时,如果此时要新增一个功能,而这个功能可能和之前50个功能都有关系,这时就可能发生破坏之前功能,或者之前其它功能点上是不可用的情况。
稳定性和高可用性。所有系统不管开源还是商业的,都需要投入大量的人力和财力。观远数据在使用Spark引擎时,也遇到过一系列数据倾斜或任务变慢的问题,最后都是通过时间积累和技术优化去克服这些难题,给用户呈现出一个高稳定高可用的产品。
Docker/Kubernetes使用问题。对于Docker/Kubernetes,偶尔会遇到内部DNS不稳定、iptables错误,端口一段时间后无法连接等问题。
数据库标准问题。每种数据库都有自己的标准,而很多数据库只规定了很少的一部分标准,对于标准中没有提到的部分,每个厂家又有自己的一套实现形式,尤其是一些日期函数、总计小计等都需要去支持。另外就是对于每一个数据库,如果要从那获取数据,一定要做到能够去增量获取,而不是查询结果立马都加载到内存中,这样就会造成机器没有内存。
面对如此多的挑战,总结来说,自研成本比采购成本要高出很多,对于IT资源有限的企业,建议可以采购成熟的BI系统。
当然,如果企业坚持自研,也可以借助Apache Spark、Kubernetes/K3S、Keycloak等丰富的开源软件。一方面企业可以利用这些软件去搭建BI系统,另一方面,企业的研发人员也可以通过这些软件去学习更多的开源知识,提高自己的架构水平。
其次,我们正处于一个马上要变革的云原生(Cloud Native)时代,在新的时代,也会诞生更多的开源项目,中国的本土开源项目发展也将会推动企业BI项目的构建。
04.
BI如何衍生数据生态
以智能决策为目标,数据可视化为最终展现形式,可以推倒出整个BI体系。那么,BI体系是如何产生数据生态?
首先当BI使用越来越多之后,任务类型也会随即增多,比如说ETL处理任务、卡片任务、订阅任务、预警任务等同时出现,随之而来的任务调度数量也会越来越多,从每天几百个到每天上千上万个。如果调度不好就可能出现某个任务一直在被调度,被多次触发的情况。而这时,就可以选用一些支持复杂调度的开源软件,比如Apache DolphinScheduler。
第二个机遇是从BI这边会演化出一些数据血缘关系和元数据管理的需求。比如说是随着BI的使用越来越多,业务人员可能同时做了上千张的可视化页面、上千个数据集、上千个ETL等,如果系统没有一个很好的管理软件,就会出现业务人员想要新增功能,又无法查询之前是否有过类似功能的情况。或者即使知道有,也不敢在原来基础上修改,害怕牵一发而动全身。长期这样恶性循环下去,就是每个人都在加重复的逻辑和计算,导致系统资源浪费和口径不一。这个时候,企业就需要一些血缘关系和元数据管理软件。
最后是质量检测和数据治理。比如说,有同事将ETL做错了出现很多Null值,或者数据更新不及时,导致后续数据错误等情况。这时,就需要一些数据质量检测和数据治理的工具,把错误扼杀在源头,减少数据排查工作。
05.
未来,BI有哪些发展趋势
从Excel、报表系统到BI,BI产品在中国市场已经接近成熟,而在未来,也会向以下几个趋势发展:
实时性:原来BI解决的都是T+1的历史数据处理,只是支撑管理层一些基本的看数需求,而随着使用的群体逐渐覆盖公各个层级的日常运营,就更需要一些实时的数据分析去做监测做管理,比如在活动期间去监测门店的实时销量和实时库存。而实时性对于很多BI产品来说具有很大的挑战性,既要考虑将实时性、离线化、批量化很好地融合在一起,又要考虑他的易用性和计算成本。
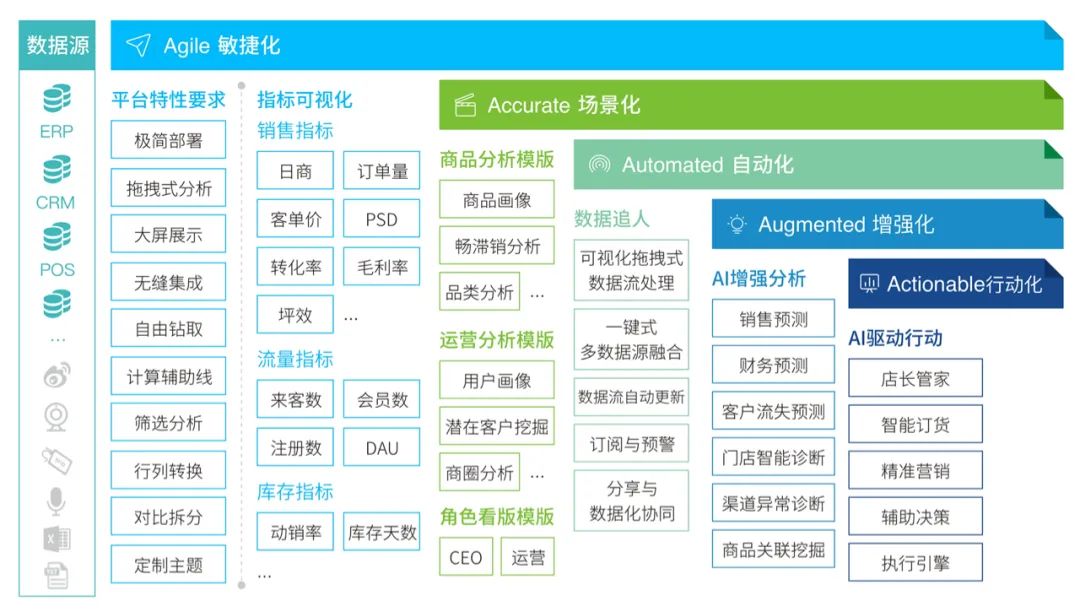
BI+AI:随着算法、算力的成熟,以及企业对于更高阶的数据分析需求的产生,未来,AI将会和BI更紧密的结合,产生更多的应用场景。观远数据一直秉承着从BI到AI的理念,并首创性地提出一整套从BI(敏捷分析)到AI(智能决策)的完整“5A”落地路径方法论(Agile敏捷化、Accurate场景化、Automated自动化、Actionable行动化、Augmented增强化),为企业构建智能决策大脑。
一站式:国外的BI厂商更倾向于做BI功能中的某一点,比如专门做可视化,而国内的企业需要的是从数据接入、数据准备、数据分析、数据可视化到分发应用的一站式服务。只有形成一个从数据到决策的闭环,才能不断优化各个环节的产出和流程。
BI作为企业决策的中枢系统,在大数据时代,将会发挥越来越重要的作用。不管是自研还是采购,企业越早规划,距离智能数据决策就更近一步。
观远产品黑科技






版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

