

观远AI实战 | 用机器学习模型洞察数据

“观远AI实战” 栏目今日正式启动,该栏目文章由观远算法天团倾力打造,观小编整理编辑,往后我们将在这里不定期推送关于机器学习,数据挖掘,特征重要性等干货分享。欢迎点击上方“观远数据”添加关注,获取手推送信息!
*本篇文章探讨主题为如何“用机器学习模型洞察数据”,由作者:观远算法天团-yyqing首发于知乎。
全文4千多字,约需要8分钟阅读时间。

这一篇分享的是最近在kaggle上习得的Machine Learning for Insights Challenge,这是一个关于模型洞察力的主题知识,字面看这个ML for insights直译为机器学习的洞察力了,在我理解来则是模型可解释性分析。本文这里主要是将我看到的有用的内容按照自己的理解翻译并记录下来。
自己在玩kaggle和工作中用到最多的主要是树类模型(lgb,xgb)和神经网络(cnn, rnn),确实很少去思考其中模型的含义和解释性。如果让我自己回答如何解释模型预测结果这个问题,我理解到用决策树的信息熵计算统计概率得出叶子节点的重要性,再加上迭代拟合残差的思路就是xgb类的算法了。而神经网络方面,我则简单的理解为求导拟合。高中课本里的一次函数二次函数的求导大家都会,神经网络只是用链式法则给若干个矩阵求导罢了,思路还是朝着目标去拟合。
如此之粗浅,见笑了,下面看看学来的新玩法。
洞察数据的使用场景
一个模型中哪些信息是可解释的?
许多人认为机器学习模型是黑盒子,在他们认为模型可以做出很好的预测,但是大家无法理解这些预测背后的逻辑。确实是,很多数据科学家不知道如何用模型来解释数据的实际意义。所以这里将会从这么几个方面来讨论:
• 在模型看来,哪些特征是最重要的?
• 关于某一条记录的预测,每一个特征是如何影响到最终的预测结果的?
• 从大量的记录整体来考虑,每一个特征如何影响模型的预测的?
解释数据的价值在哪里?
从五个方面可以体现出“用模型解释数据”的价值。
价值一:调试模型
一般的真实业务场景会有很多不可信赖的,没有组织好的脏数据。工程师在预处理数据时就有可能加进来了潜在的错误,或者不小心做出了data leak,考虑各种潜在的灾难性后果,debug模型的思路就尤其重要了。当你遇到了用现有业务知识无法解释的数据的时候,深入了解模型预测的模式,可以帮助你快速定位问题,anyway,这一条对算法工程师意义重大。
价值二:指导特征工程
特征工程通常是提升模型准确率最有效的方法。通常涉及到到用各种算法操作原始数据(或者之前的简单特征),得到新的特征。有时候你完成特征工程的过程只用到了自己的直觉或者业务知识。其实这还不够,当你有上百个原始特征的时候,或者当你缺乏详细业务背景知识的时候,你将会需要更多的指导方向。
这个预测放贷结果的kaggle竞赛就是一个典型的例子,这个比赛有上百个原始特征。并且因为隐私原因,特征的名称都是f1, f2, f3等等而不是具有描述性的英文单词。这就模拟了一个场景,你没有任何业务方面直觉的场景。有一位参赛者发现了某两个特征相减f527, f528可以创建出特别有用的新特征,用到这个新特征的模型比其他模型优秀很多。但是当你面对几百个特征时,你如何创造出同样优秀的特征呢?这里将要介绍的用模型寻找重要特征的方法,用模型洞察两个特征相关性的方法,都会指导工程师在创作出优秀的特征。
价值三:指导未来数据收集方向
对于从网上直接下载来的数据,你肯定是控制不了收集方案的。不过很多公司和机构都会用数据科学来指导他们从更多方面收集数据。一般来说,收集新数据很可能花费较高或者难度很大,所以大家很想要知道哪些数据是值得收集的。基于模型的洞察力分析可以教你很好的理解已有的特征,这将会帮助你推断什么样子的新特征是有用的。
价值四:指导人们决策
一些决策是模型自动做出来的,比如电商网站决定在你看到的网页上展示哪些商品。其实在更高层面的很多重要决策是由人来做出的,而对于这些决定,模型的洞察力会比模型的预测结果更有价值。
价值五:建立信任
很多人在做重要决策的时候不会轻易的相信模型,除非他们验证过该模型的一些基本特性,这很合理。实际上,把模型的可解释性直观的展示出来,如果这些洞察结果可以匹配上人们对数据的理解,那么这将会建立起大家对模型的信任,即使是面向那些没有数据科学知识的人们。
Permutation Importance
一个最基本的问题大概会是什么特征对我模型预测的影响最大呢?这个东西就叫做“feature importance”即特征重要性。我们有很多方法来衡量特征的重要性,这里将会介绍一种方法:排列重要性。这种方法和其他方法比起来,优势有:
• 计算速度快
• 广泛使用和理解
Permutation Importance原理
排列重要性,是在model训练完成后才可以计算的。简单来说,就是改变数据表格中某一列特征的数据排列,看其对预测准确性的影响有多大。分三个步骤:
• 训练好模型
• 拿某一列特征, 然后随机打乱顺序。然后用模型来重新预测一遍,看看自己的metric或者loss function变化了多少
• 把上一个步骤中打乱的特征列复原,换另外一个特征列重复上一个步骤,直到所有特征列都算一遍
Permutation Importance应用解读
这里我们的例子是根据FIFA2018的比赛统计信息来预测一个球队中是否会包含最佳球员。如何建模不是本文的重点,我们会用很简单的模型来举例。
代码片段1:载入数据,训练好随机森林模型
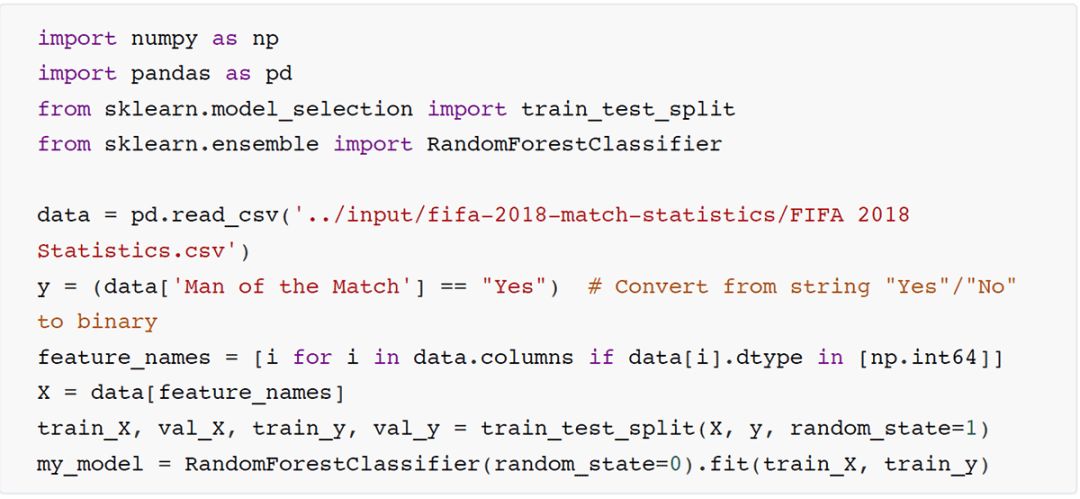
代码片段2:用eli5库,计算排列重要性

结果如图:
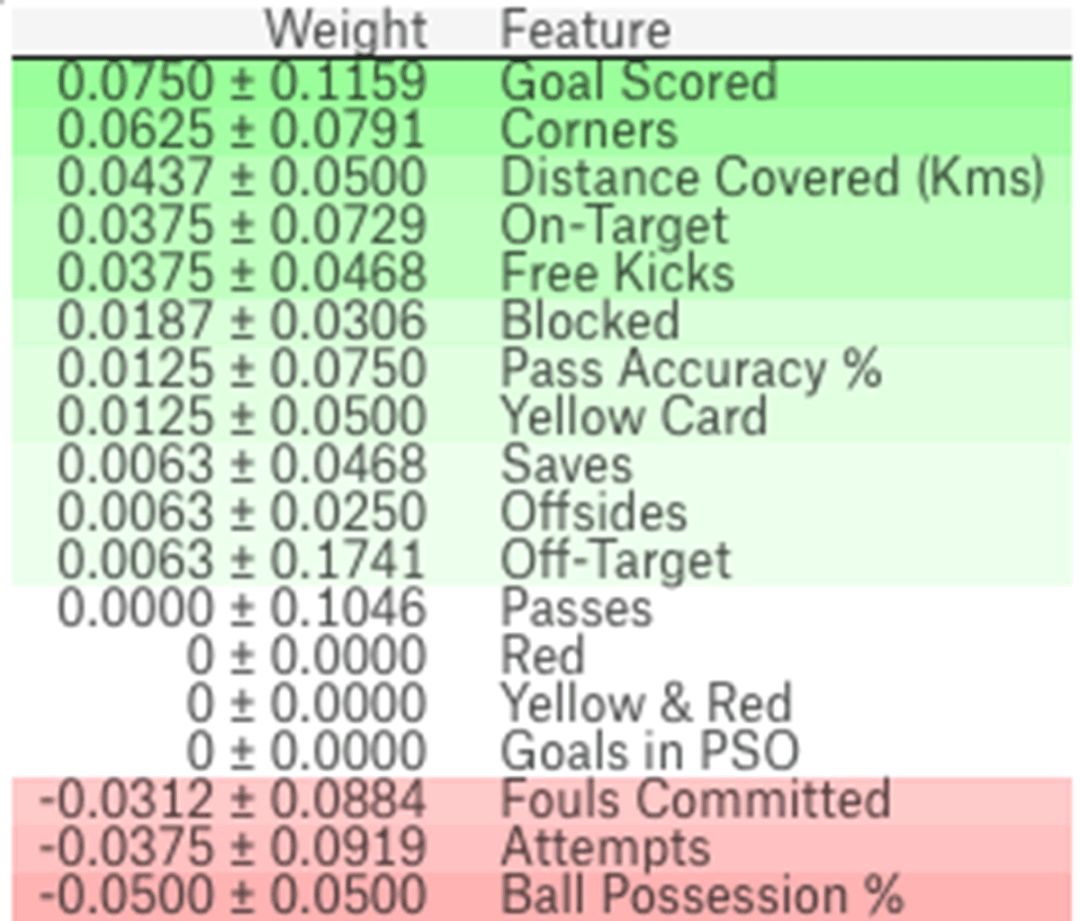
在上图中,顶部的是对结果影响最大的,底部的是影响最小的。因为是随机的打乱排列计算出来的,所以多做了几次随机打乱的操作之后,对metric的影响大小的数值是用mean加减std这两个数字来表示的。
偶尔会看到重要性的值是负数,这意味着那一列特征被打乱后比打乱前的预测准确率还要高。这意味着这列数据基本没啥用。在较小的数据集里会更容易出现这种情况。
这里例子里,最重要的特征是“Goals scored”即进了多少个球, 这看起来是合理的。当然,足球运动员对这些特征的重要性的顺序会有自己独到的见解。
Partial Dependence Plots
特征重要性可以告诉你哪些特征是最重要的或者是不重要的,而Partial Dependence Plots(后文简称为"PDP")可以告诉你一个特征是如何影响预测的。
如果你对线性回归或者逻辑回归比较熟悉,那么partial dependence可以被类比为这两类模型中的“系数”。并且partial dependence在复杂模型中的作用比在简单模型中更大,更容易抓出更复杂的特性。
PDP原理
和permutation importance一样,PDP是需要在模型训练完毕后才能计算出来。同样还是用FIFA2018的数据集,不同的球队在各个方面都是不一样的。比如传球数,射门数,射进数等等。一眼看过去,很难区分这些特征对结果的影响有多大。为了清晰的分析,我们还是先只拿出某一行数据,比如说这一行数据里,有控球时间50%,100次传球,10次射门和一个进球。我们将会用已有模型来预测结果,将这一行的某一个变量,反复的进行修改和重新预测,比如将控球时间修改从50%修改为60%,等等。持续观察预测结果,在不同的控球率时有什么样的变化。
这里的例子,只用到了一行数据。特征之间的相互作用关系通过这一行来观察可能不太妥当,可以考虑用多行数据来进行试验,然后根据平均值画出图像来。
PDP应用解读
代码片段3,还是载入数据并且训练好决策树
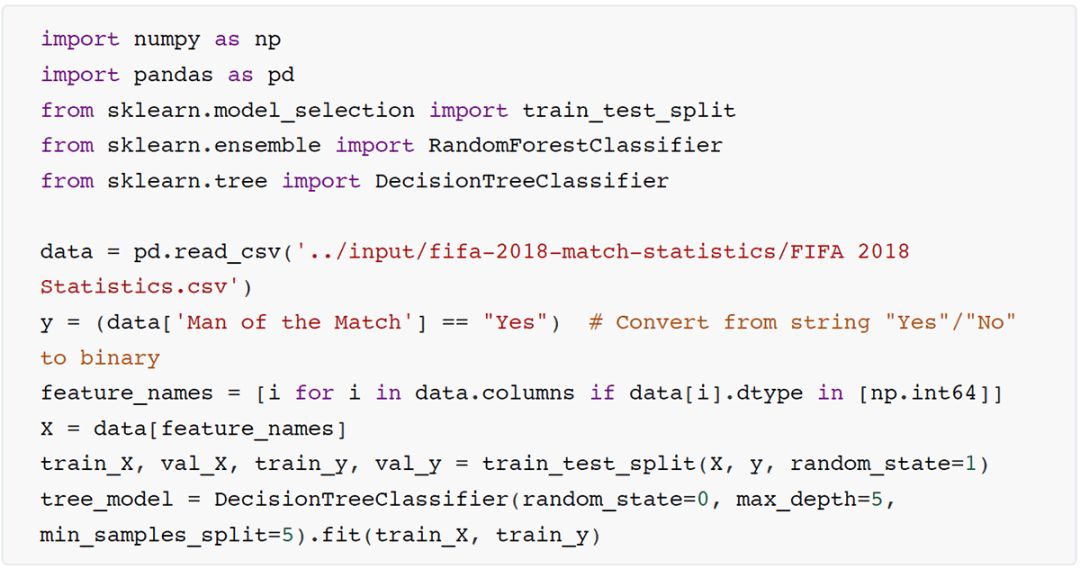
代码片段4,决策树结构


这个图大意如下:1.拥有子节点的节点里的信息,行标记的是如何决策拆分的;2.每个节点下面几行的数据,都是表示该节点上的已经确定好的value
代码片段5,用PDPBox库来画出PDP

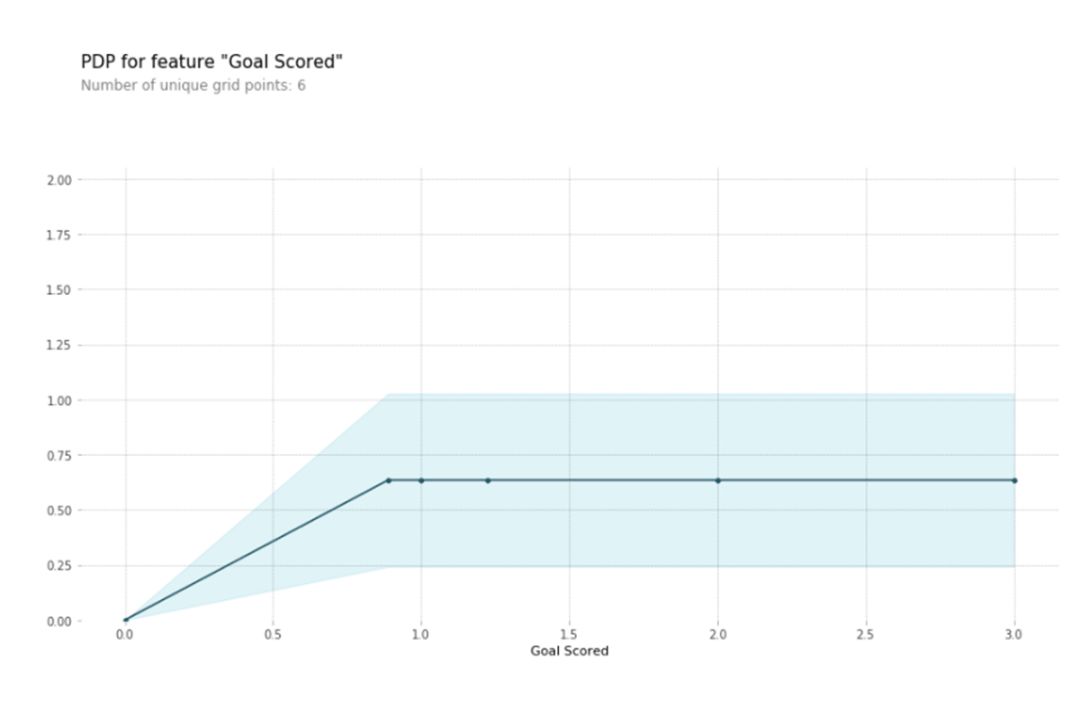
在解读这个图的时候,有几点是值得注意的:,y轴是预测结果的变化量,第二,蓝色阴影区域代表了信心的大小。从这幅图可以看出,进球数的增加肯定可以增加拥有最佳球员的概率,但是进更多的球的时候,对这个概率影响不大了。
接下来我们换一个模型,然后换一个特征来看看:
代码片段6,随机森林模型,特征用跑动距离

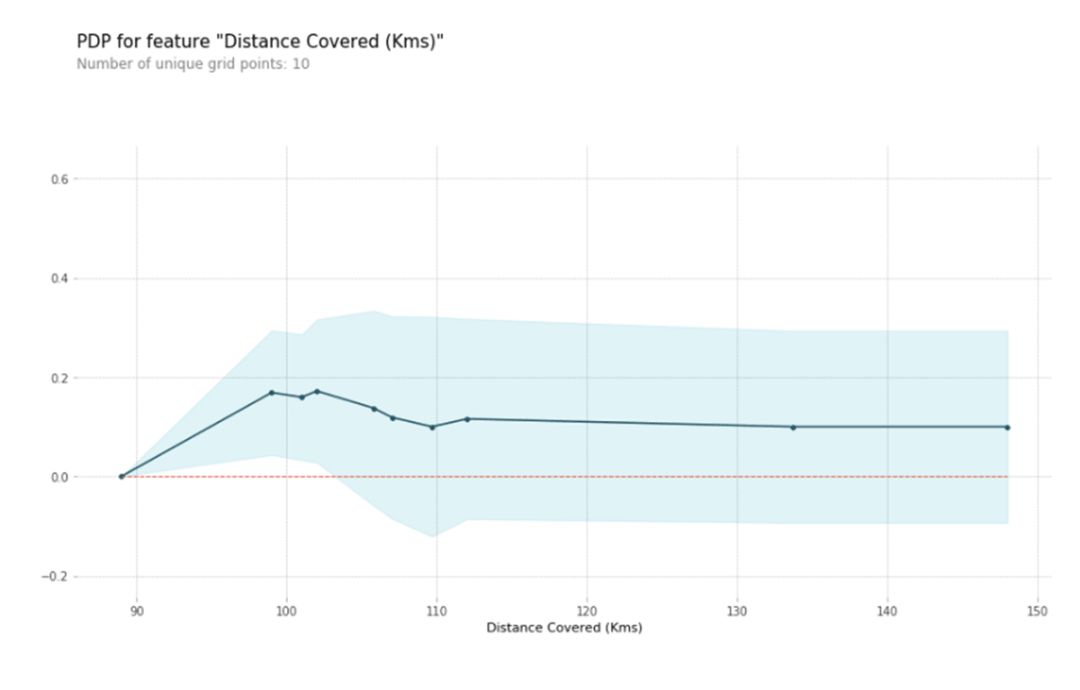
随机森林模型认为差不多跑动距离大约100KM左右是最容易获得MVP的,跑动距离多了概率会下降一点。符合我个人想法的,毕竟足球运动员如果跑太多了,会很累,然后就会影响发挥吧。
2D PDP
如果你对特征之间的相互关系感兴趣的话,那么2D PDP图肯定用得上了。
代码片段7,决策树模型,同时使用进球数和跑动距离两个特征

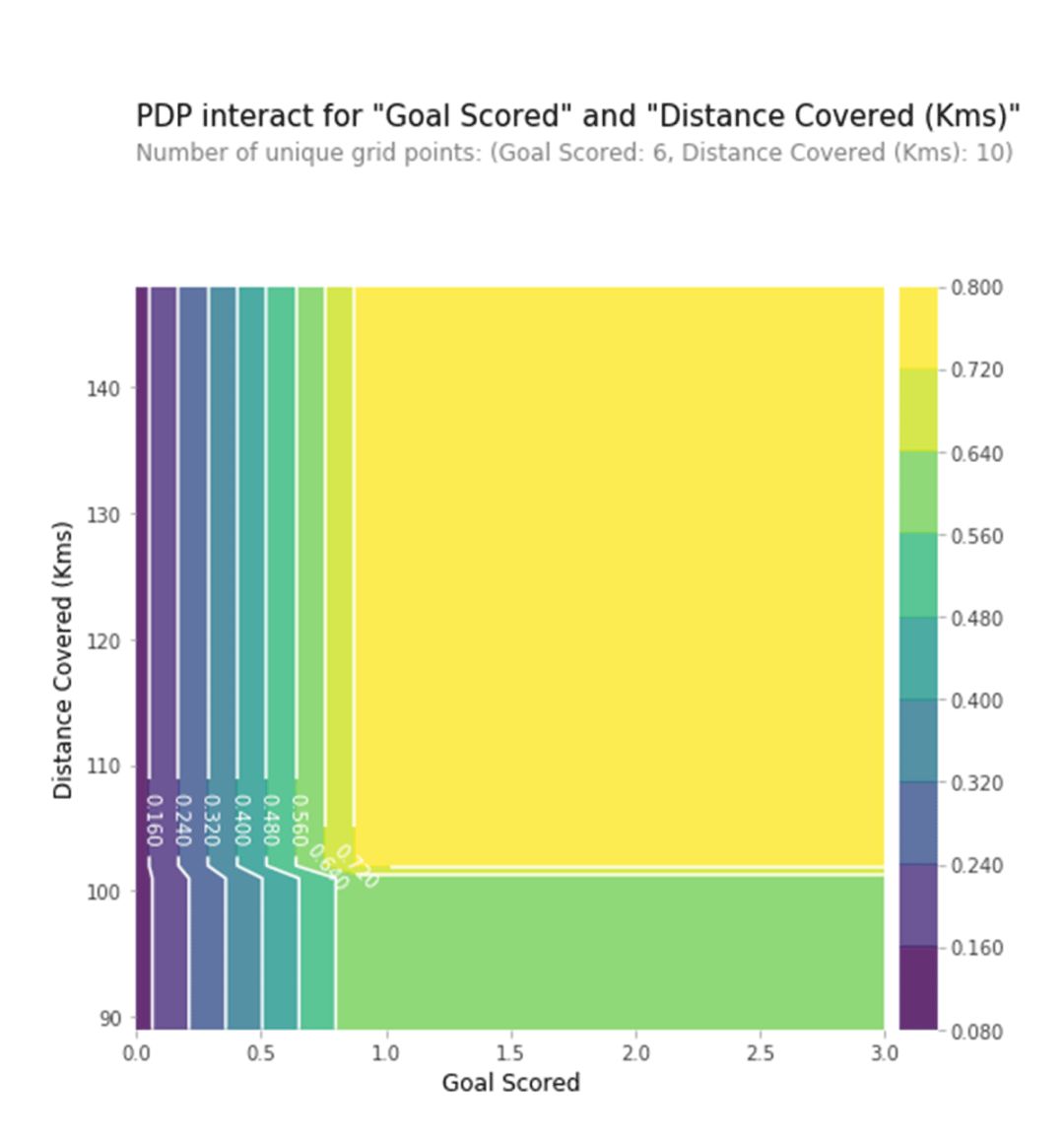
上图展示了进球数和跑动距离的各种组合情况下的预测结果。例如,我们看到了最高的预测值来自于当一个球队进了一个球并且跑动距离接近于100km的时候。当进球数为0的时候,跑动距离无论多少都没啥关系了。这个图能清晰的显示出,跑动距离在有进球的时候才会影响预测结果。
SHAP Values
前面已经介绍了两种技术,现在将要介绍的技术可以让你观察到某一个item预测中各个特征对预测结果产生的影响:SHAP values。这个技术应用场景可以是:1. 一个模型说银行不愿意贷款给你,但是在法律层面上银行需要基本的解释为什么拒绝了你的贷款申请;2. 一个医疗健康中心想要知道在某一类疾病患者中,每一个患者的最大的病因是什么,然后医生可以对每位患者对症下药。
SHAP Values原理
NIPS论文地址:A Unified Approach to Interpreting Model Predictions,这个计算SHAP值的想法来自于博弈论中的shapley value(shapley单词源自于2012年诺贝尔经济学奖获得者Lloyd Stowell Shapley)。膜拜了一圈,很深奥的样子,我理解的大意就是:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAP baseline
value。
SHAP值的计算原理如下:

他会有一个baseline value,然后他给出所有特征基于这个baseline的值是多少,当然也会有最后预测值是多少。
SHAP Values应用解读
这里我们用到的库是Shap ,用到了LIME方法来加速计算出SHAP Values.
代码片段8:训练好随机森林
代码片段9:计算出单次预测的SHAP值

上面计算出来的shap values里有两个数组。个数组里存放的是给预测值负面影响的数字,第二个数组里存着正面影响的数值。直接查看两个数组的数字可能会有点蠢,所以shap library上场来一个漂亮的可视化。可视化之前,我们先看一下预测结果:my model.predictproba(data for predictionarray)的输出是array([[0.3, 0.7]]),可以看到这个队伍有70%的概率有成员可以获得最终的MVP。
代码片段10:可视化

可以看到如下图所示:

如何解读呢,我们预测值是0.7,基准值是0.4979,增加预测值的特征颜色是红色,长条的面积代表了数值的大小。降低预测值的特征颜色为蓝色。可以看到最大的增加预测值的特征是“进球数”为2。但是我们可以看到控球率这个还比较有意义的特征在这里是降低了预测值。
如果你仔细观察我们创建SHAP values时的代码,你会注意到我们用的是一个TreeExplainer。shap库其实对其他的模型也有对应的解释器(explainers):
• shap.DeepExplainer是用于解释深度学习模型的
• shap.KernelExplainer可用于解释所有的模型,尽管它运行时间比其他解释器时间长一点,但是它能够给出一个近似的的Shap values.
结语
总结一下,这里介绍了三种方法Permutation Importance,Partial Dependence Plots,SHAP Values,分别都有各自的python库可以调用,以达到洞察数据的目的,希望大家看完之后能有所收获。
文中如有描述错误的地方请多多包涵,可以在留言板指出改正。
有任何机器学习相关的知识都欢迎探讨。

yyqing
关注AI与数据挖掘等方向
知乎号:yyqing | Blog: yyqing.me
Kaggle Rankings Top 1%
观远算法天团又称余杭区五常街道数据F4,成员多来自于海外以及国内大学、浙江大学、上海交大等知名学府,并有大数据产品与技术研发的从业背景。2018年凭借先进的算法能力,在大中华区智慧零售( Retail)AI挑战大赛中,两度斩获冠军,并从1500多家创新公司中脱颖而出,全票入选腾讯AI加速器第二期。作为本专栏特邀产出者,观远算法天团将在未来持续为大家分享更多精彩干货,敬请期待!
观远数据| 观点精选
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

