
观点 | FiBiNET: paper reading + 实践调优经验
《观点》栏目是由观远数据倾力打造的一档技术类干货分享专栏,所有内容均来源于观远数据内部员工,旨在为数据分析行业输出指导性的知识体系。

在传统的embedding stage加入了一个SENET层对已经完成embedding的特征再做了embedding,得到了与特征重要性(Feature Importance)相关的信息。 再把这些信息连同原始的embedding feature一起结合起来生成新的特征向量后,不使用传统的inner product或Hadamard product方法,而是选择了结合二者的一种新的bilinear interaction方法来获得特征之间的联系。
框架
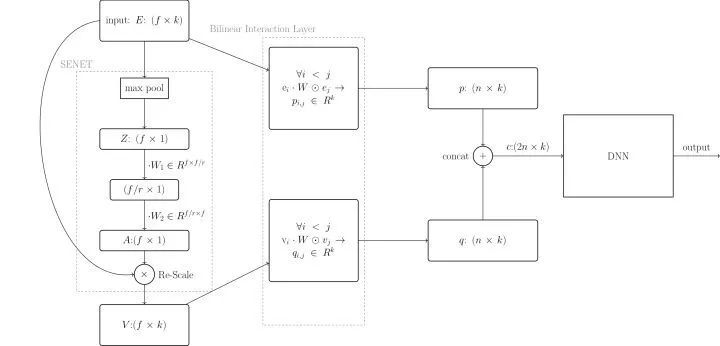
 个稀疏高维的原始特征数据首先经过一层embedding层得到低维稠密特征构成的实数向量
个稀疏高维的原始特征数据首先经过一层embedding层得到低维稠密特征构成的实数向量  ,其中每个
,其中每个  ,
,  为embedding层的维度,有些实现中为参数embedding_size;
为embedding层的维度,有些实现中为参数embedding_size;把  作为输入传入一个类似于SENET的结构,得到这些特征的权重向量
作为输入传入一个类似于SENET的结构,得到这些特征的权重向量  ,
,  为标量,所以
为标量,所以  ;
;把1的结果即原来的  乘以2得到的权重
乘以2得到的权重  得到一个新的embedding向量
得到一个新的embedding向量  ,维度不变,
,维度不变,  ;
; 经过bilinear函数的转换得到一个包含特征之间的关联的向量
经过bilinear函数的转换得到一个包含特征之间的关联的向量  ,其中
,其中  的大小为特征数
的大小为特征数  的二元组合数
的二元组合数  ,后面会详细讲。而每个
,后面会详细讲。而每个  保持不变;
保持不变; 经过bilinear函数的转换得到一个包含特征之间的关联的向量
经过bilinear函数的转换得到一个包含特征之间的关联的向量  ,
,  同上,依然有
同上,依然有  ;
;在combination层把4和5的输出  和
和  简单的连接为
简单的连接为  ;
;最后把  送到多层全连接的神经网络结构,也就是我们通常说的DNN,得到最终的输出。
送到多层全连接的神经网络结构,也就是我们通常说的DNN,得到最终的输出。

SENET-like Layer
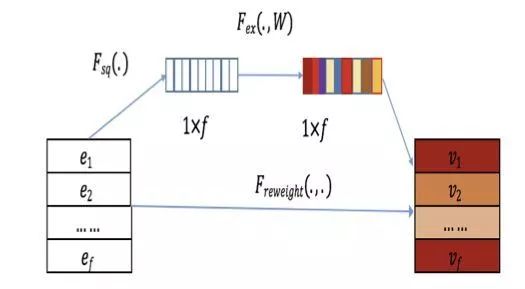
 得到加权后的
得到加权后的  。
。  做一次最大池化,原文中这个地方给出的是一个平均池化的公式,也是原始的SENET用的池化方法,然而FiBiNET用到的实际是类似于
做一次最大池化,原文中这个地方给出的是一个平均池化的公式,也是原始的SENET用的池化方法,然而FiBiNET用到的实际是类似于
 压缩为向量
压缩为向量  ,其中每个
,其中每个  都是标量。
都是标量。 进行一次降维到
进行一次降维到  维再进行一次升维恢复到原来的
维再进行一次升维恢复到原来的  维,得到特征的权重得分
维,得到特征的权重得分  ,每个
,每个  为标量,整个过程可以表示为
为标量,整个过程可以表示为 
 和
和  为activation function,权重矩阵
为activation function,权重矩阵  和
和  都在训练时期通过动态的学习获得,并在之后参与表现每个
都在训练时期通过动态的学习获得,并在之后参与表现每个  的权重,
的权重,  表示维度的缩减比例(reduce ratio)。
表示维度的缩减比例(reduce ratio)。 和
和  按照类似于Hadamard product的方法对其中的
按照类似于Hadamard product的方法对其中的  个元素进行element-wise的相乘得到SENET的最终产出
个元素进行element-wise的相乘得到SENET的最终产出  ,如果把
,如果把  视为一个权重向量,那么这一步也可以被叫做加权或rescale
视为一个权重向量,那么这一步也可以被叫做加权或rescale
 ,其中
,其中 
 与原始的输入
与原始的输入  分别经过Bilinear-interaction层后得到
分别经过Bilinear-interaction层后得到  和
和  连接起来就是DNN部分的输入。
连接起来就是DNN部分的输入。 )或者Hadamard product(
)或者Hadamard product(  )去做。由于这两种方法过于naive,例如
)去做。由于这两种方法过于naive,例如 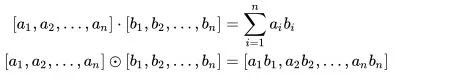
 和
和  之间加入了一个
之间加入了一个  的权重参数矩阵
的权重参数矩阵  进行这样的计算
进行这样的计算 

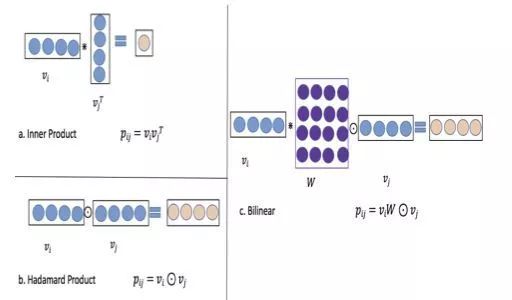
 ,所以共有
,所以共有  个
个  的组合需要经过上面的计算。最后
的组合需要经过上面的计算。最后  作为这一层的输出结果,
作为这一层的输出结果,  。
。 在训练的过程中可以动态的学习到特征之间的组合关系,无疑增加了模型的表达能力。当然关于要选择多少个
在训练的过程中可以动态的学习到特征之间的组合关系,无疑增加了模型的表达能力。当然关于要选择多少个  也在后文中具体讨论了3种可选择的做法:
也在后文中具体讨论了3种可选择的做法:Field-All: 所有的向量都共用一个  ;
;Field-Each: 每个在左边的  有一个对应的
有一个对应的  ,一共需要训练
,一共需要训练  个
个  ;
;Field-Interaction: 对每个  单独训练一个特定的
单独训练一个特定的  ,共有
,共有  个
个  需要训练。
需要训练。
 输出了
输出了  ,从
,从  输出了
输出了  ,把它们组合为
,把它们组合为  作为DNN的输入即可,后面的DNN就比较中规中矩,不再赘述了。
作为DNN的输入即可,后面的DNN就比较中规中矩,不再赘述了。
一些实现和使用的反思
因为模型本身不够深也不算复杂(原文是3层hidden layer,DeepCTR默认2层),GPU对它几乎没有加速。 使用Field-Each方式能够达到最好的预测准确率,而且相比默认的Field-Interaction,参数也减少了不少,训练效率更高。当然,三种方式在准确率方面差异不是非常巨大。 reduce ratio设置到8效果最好,这方面我的经验和不少人达成了共识,SENET用于其他学习任务也可以得到相似的结论,当然这里很玄学,我没有测试足够多的数据集,这部分可能需要根据个人任务在tuning过程中自己探索。 使用dropout方法扔掉hidden layer里的部分unit效果会更好,系数大约在0.3时最好,原文用的是0.5,请根据具体使用的网络结构和数据集特点自己调整。
猜 你 喜 欢



版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

