
















算法男神天团:记一次愉快的黑客松之旅

在一个月黑风高的夜晚,我正在王者峡谷里肆意驰骋,眼看就要一波上高地,忽然老板在群里丢过来一个黑客松比赛的邀请,说是顶级level+真实场景,跟我们做的新零售方向挺接近的,可以考虑参加一下。
看了下比赛信息,是联合百威英博,可口可乐这些零售行业大佬一起举办的,提供云计算平台资源和技术支持,零售大佬提供他们业务运营的真实数据,然后根据他们的需求来做数据分析,预测等创新解决方案。这个还是相当亦可赛艇的,毕竟我司行业专家如云,还有我这样有着丰富数据比赛(观摩)经验的选手,强强联合,必须要全军出击一波了!
于是在老板的号召下,余杭区五常街道数据F4算法男神天团迅速组建成立,大家都是摩拳擦掌,蠢蠢欲动,静待正式比赛的到来……
转眼来到了正式比赛的日子,我们一行4人浩浩荡荡地抵达了国际化大都市上海。比赛地点设在高端大气上档次的创投加速器办公楼,进门左边是个咖啡馆,右边是加速器办公区,中间是这次比赛的活动展示大厅,两边还有各种涂鸦墙,书架,宣传海报展板,一股充满活力的创业极客气息扑面而来!
上海站的比赛是百威出题,所以现场还摆了好多百威英博旗下各个品牌种类的啤酒。接下来两天就要在这里边喝啤酒边在Azure云上肆意驰骋,想想还有点小激动呢!
签到进场之后主办方和百威进行了简短的公司背景及比赛介绍,然后的技术MM展示了他们强大的Azure云平台,大厂就是不一样,从大规模数据存储到计算,从便捷的Data Science VM到各种开箱即用的智能API,真是琳琅满目,应有尽有。瞬间感觉到这次比赛赠送的150刀云资源代金券很有料啊!
做完各种介绍,比赛就正式开始了!这次比赛一共有三道题,我们大致看了下原始数据和优化目标后,决定锁定POS forecasting这个我们比较有经验的课题来做。
这个题给的数据是百威全国各个渠道门店一年来的POS销售数据,目标是预测下一个月各个门店各个产品的销量。门店总数有430+,产品总数有820+,总的数据量有400多万条每日销量记录。这个数据量级不算很大,所以我们打算就用jupyter notebook来做主要的分析预测工作了。早上剩余的时间大家分头做数据探索,尝试理解一下其中的各种业务逻辑以及数据中隐藏的问题或者规律。
不得不说比赛组织者们还是很用心的,的同学们过来询问了几次有没有碰到环境搭建的问题,百威的数据专家们也来询问了下我们对数据和赛题本身有没有什么疑问,真是无微不至的关怀……现场还准备了好多零食水果,啤酒饮料,导致中午组织方帮忙点的高级外卖(小南国)我们都吃不太下……
吃过午饭,大家都逐渐开始进入高速运作的状态了!我们根据比赛的几个评判方向做了下简单的分工:我们的产品业务专家主要来负责商业前景以及客户业务结合度方面的设计考量,另外两位技术达人主要负责数据探索,特征工程,参数调优,而我主要专注于新颖性方面的探索(划水)。从我的文风就可以看出,我负责这块内容简直是天造地设,完美契合啊!
由于时间比较紧,各项工作都是并行展开,一边用着基础数据跑模型,一边查看异常数据点,预测误差组成,一边还在不断地设计添加新特征。感谢Azure云的服务器,让我们可以同时在本地笔记本和云端做并行开发,尤其是后面到了各种吃饭,休息的时候还可以不间断地运行参数搜索优化,再也不用总是抱着笔记本跑模型了,提高了不少效率。
一下午的hacking转瞬即逝,到晚上赛场关门的时候我们已经把MAPE从直接用均值预测的0.74提升到了单GBRT模型的0.3左右,特征数从原始表的5个也加到了30个以上。
这次比赛的数据都是脱敏的,也就是只有门店,商品ID,所以很多诸如门店位置,天气情况,当地收入水平,各种体育赛事信息,搜索引擎的关键词趋势等等开脑洞的特征都没有办法加入,我的特长无处安放啊!所以只能另辟蹊径,开始了我的paper阅读之旅!晚饭后回到酒店,我基本就是在不停地找相关的解决案例和优化思路,对各大公司研究机构发的论文进行地毯式搜索,然后尝试着用我的三脚猫代码水平实现一下……
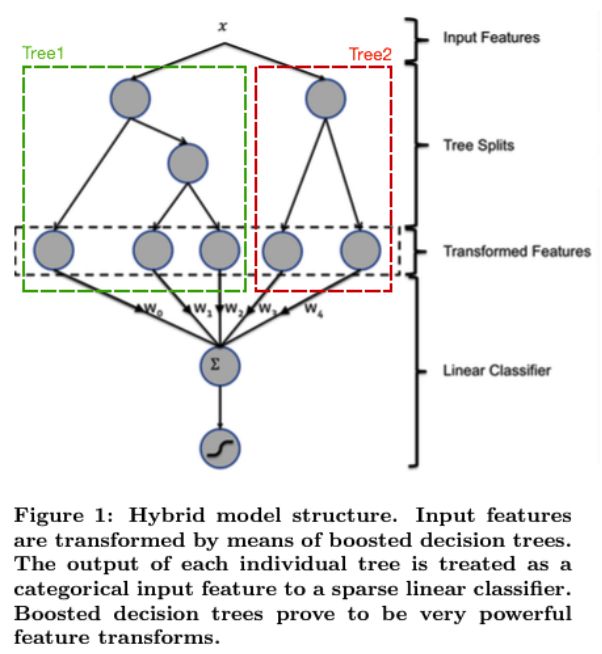
之前看到Facebook论文说可以用XGBoost叶子结点信息来生成新特征,结合LR提升最终CTR预测效果,我尝试了下发现这个方法对于我们的数值回归问题来说效果并不明显,可能需要进一步做数据预处理。
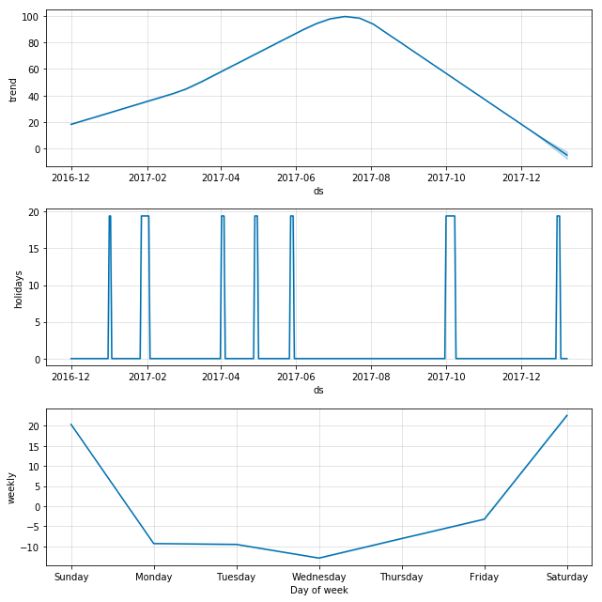
我们之前项目中有用到过的GAM时序预测库Prophet,也拿来跑了一遍看看门店,商品的时序规律如何,发现效果还行,各种components的图画出来令人信服,可以后面作为一个简单的基础模型来进行融合。
原本有做过DTW时序距离加KMeans来对某些维度做聚类,比如这次比赛数据中热销商品跟冷僻商品的销售模式很不一样,聚类一方面可以提供新特征,另一方面也可以考虑直接拆分数据建立子模型。
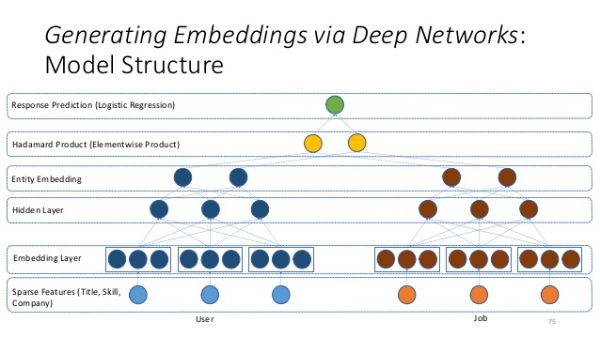
不过在方案搜寻中发现了可以更加高效地实现从高维稀疏特征来自动构建特征向量空间的embedding方法!背后的思想类似于著名的word2vec在自然语言处理领域的应用。比如Yoshua Bengio的学生们参加Kaggle比赛时就用到了这个方法,取得了不错的效果。
我也试着用Keras + TensorFlow在我们的基础特征上实现了一下看看效果。虽然深度学习相关方法看起来很吸引人,感觉不用做复杂的特征工程了,但实际上各种网络的参数还是相当多的,embedding层的shape,全连接层的数量和大小,dropout设多少,要不要做batch norm,激活函数用什么,预测值要不要做成分类问题,还是做归一化转成sigmoid处理?简直成了十万个为什么……目前我所知的最好办法还是结合一些经验与猜测,直接跑试验来验证效果了。可惜这次比赛提供的机器没有GPU,神经网络跑起来速度感人,粗略跑了2个网络效果都没有我们的XGBoost baseline好,如果要放进结果应该也是很低的权重了。
不过这个embedding还是可以一秀的嘛!拿出t-SNE来做个降维,然后就把各个月份,各个门店,各个商品的相关度画出来了,起码这部分工作没有白费……
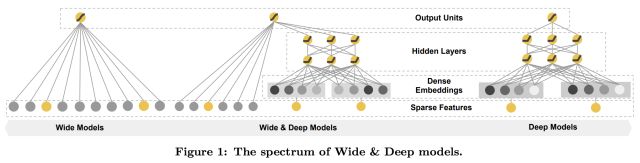
还有一个很类似的工作,来自于Google的Wide and Deep Learning,通过联合训练的方式融合线性模型与DNN模型,看起来很适合我们这种结合时间窗口特征的问题。不过限于时间关系没有进行进一步的实现与测试。
另外还有许多没有来得及尝试的思路,比如Uber发表的用LSTM做预测的方案,不过其中也提到了单个LSTM网络的效果并不好,如果要实现全套的特征工程 + LSTM Autoencoder + 第二层LSTM,无论是代码量还是运算量上都有些不太现实,最终还是放弃了。Uber还提出了一个更加Fancy的BNN网络结构,使用LSTM做time series的embedding,然后再把这个embedding与外部特征结合来做预测。但考虑到我们这个问题中的维度主要是在门店,商品组合上(14000种可能),而时间维度的取值要少的多(365天预测31天),猜测使用这个方案的效果并不一定会很好,所以也没有进行测试了。
Hacking起来真是完全感觉不到时间的流逝了,不知不觉已经到了深夜,在此要向被我们讨论打扰到的汉庭酒店房客们致以歉意。总体来说进展喜人,队友那边特征优化的效果已经突破了0.3大关,做完误差分析感觉综合模型进一步提升的空间已经不大,所以我们决定把重点转向几个数据中发现的难点进行攻克。比如对于从未出现过的门店和商品,尝试建立子模型或者简单规则解决,还有偶发的巨额销售情况,尝试通过数据分析来找是否有隐藏的规律。超参数调优这块我们使用了贝叶斯优化的方式来提升搜索效率,这个基本也是自动执行,不需要投入多少人力。
但是漫漫长夜,无心入睡怎么办!我们作出了一个大胆的决定,再做另外一道题目!
于是我们在凌晨1点又开启了对另一道STR Misreporting的分类问题的探索研究。与此同时我开始做一些收尾的性能提升工作,比如模型融合。
融合的时候突然想起来除了XGBoost,也出过一个LightGBM的库啊!在Azure的VM上一跑import lightgbm,顺利通过,看来是预装好的,那为何不试试看呢,说不定有奇效呢!直接用sklearn的方式调用了下LightGBM,发现不行,看了下文档发现还是有些不一样,花了几分钟修改,模型顺利地跑了起来!没过10来秒就出了结果,我去怎么这么快?看了下MAPE稍微有点高,改了改boost round和num leaves,性能一下子就接近XGBoost了,而且训练速度快了好多!从原来的470秒下降到了19秒,简直逆天……还能利用GPU(虽然XGBoost也可以),应该能进一步提升速度,看来以后可以多试试这个库了!这也算是本次比赛一大意外发现吧。最后用了XGBoost, LightGBM和Random Forest做融合,MAPE达到了0.23,感觉算是比较满意的结果了。
接下来我也投入到了答辩ppt的制作中去,把各种数据探索,特征重要度的图都用seaborn,missingno这些高逼格绘图库重新画了一遍,把整体的分析处理流程,尝试的各种解决方案做了归纳总结,还把所有参考到的资料都从Google Scholar上摘取了专业的引用格式进行整理,一通忙活到4点,终于还是扛不住去睡了。只剩下那位看新题的队友还在坚持奋战……
一觉睡到7点多,看到做STR题目的队友在群里贴了几个问题,一下就清醒了,起来继续讨论。第二天只剩下早上的时间来完善结果,还要准备答辩,还是很紧迫的。为了让我们的方案在技术可实现性方面更加成熟,我又赶紧画了几个架构图,可以用于生产环境的规划和部署。产品行业专家也在不断细化总结我们在零售行业的经验和方案,力求更加贴近业务,体现商业价值。STR方向的同学仍在不断努力,尝试通过SMOTE采样,交叉验证和贝叶斯优化寻找进一步提高预测准确率的突破口……
中午12点左右,我们最终定稿,开始答辩准备。这次参加答辩的评委有不少是来自百威的数据业务专家,都是国际友人,所以整个答辩需要使用英语。想想自从离开外企,已经有4年没用英语做演讲展示了,还是有点紧张。不过还好我们分了3个人分别上台演讲,每个人可以准备自己最熟悉的部分,减少了不少压力。答辩之前百威的数据专家先到每个团队收集最终的数据,之前其实我们并不知道别的队做的结果如何,不过看百威的人对我们的结果还挺感兴趣的,看起来是个好兆头,也给我们上台展示增强了不少信心。
终于到了最终答辩评比环节,我们是七支队伍中个上场答辩的!总体来说发挥还可以,就是时间没有控制好,加上内容放得太丰富,超出了16分钟的限定……但是总体展示效果还是挺不错的,刚讲完下来就有另外团队的同学来跟我讨论一些技术上的细节,看来是受到了认可的哈哈。
其他几只队伍的答辩也很精彩,无论是分析思路上还是模型设计上都有不少可以学习借鉴的地方。其中给我印象最深的是一面团队,细致的探索分析与预处理,简洁高效的多重模型组合,最终的预测效果也非常不错,一看就是经验丰富的老手。而且他们团队的背景也是相当吓人,基本都是,北大,斯坦福,牛津,港科大这类的全球顶尖名校,作为老和山职业技术学院的学渣我有点瑟瑟发抖……
最终,两天的努力拼搏还是换来了令人满意的结果,评委正式宣布,冠军队伍是Guandata!!!
终于可以开瓶啤酒庆祝一下了!然后还接受了的采访,留了合影,还有各位业界大佬们主动过来搭讪,交流业务需求,我们更加深切地体会到了实际业务与比赛中简化的情况相比还会有更大的挑战,当然也有着更多可能与无限商机等待我们去开拓!
最后,当然还是要强势植入一波我观的招聘广告!加入我们“观远大神天团”,推荐入职转正可以报销5000元机票!
观远数据| 观点精选
【行业资讯】智能零售解决方案黑客松上海站夺冠!
【可视化数据】图表用得妙,年终好汇报
【数据处理系列】年度账单原来是这样产生的!
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

