



为什么啤酒和尿布摆在一起销售?关联算法来解答!
快要过年了,朋友们的聚会越来越多,大家总免不了来上几瓶啤酒。我们今天就来谈谈一个跟啤酒有关的零售话题:啤酒和尿布的故事。这是一个非常经典的老故事,却是发生在零售大鳄沃尔玛的真实案例:尿布和啤酒赫然摆在一起出售,这个奇怪的举措却使尿布和啤酒的销量双双增加了。
原来,美国的妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布。而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起购买的概率是比较高的。
我们在跟一些零售企业的负责人沟通需求的时候,他们总是津津乐道于这个故事,也很想在自己的店铺、卖场应用这样的案例,却不知道到底应该如何去挖掘不同产品间的潜在联系。
那到底沃尔玛是怎么在茫茫的历史交易数据中发现尿布和啤酒之间的关系呢?是不是觉得网上说的Apriori和FP-growth等等关联算法太过高深莫测、遥不可及?别怕,今天小刚就来告诉你一个依托观远数据平台的,一步一步可操作的销售关联分析。
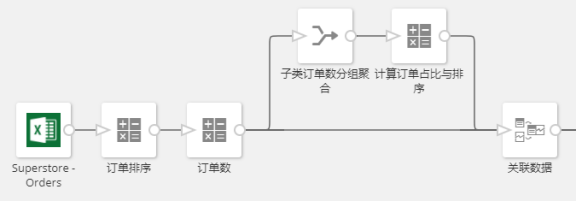
计算商品订单数
首先,对于一般的零售店铺来说,最有关联挖掘价值的肯定是销售情况最好的一些商品。不管是这些商品本身的销量提升,还是它带来的其他商品的关联销售的提升,其效果相对于低频销售的商品都是最好的。不过需要指出的是,这边的销量情况不是指销量,而是包含该种商品的订单数。
因此步,我们需要对所有商品统计它们在所有订单中出现的次数。需要注意的是,这边计数时是需要去重的:比如商品A在一个订单中数量为10,但计数时只能按1次计算。
02
对商品订单占比进行排序
有了商品的订单数,我们就可以先对所有商品订单数或所占的订单比例进行排序。
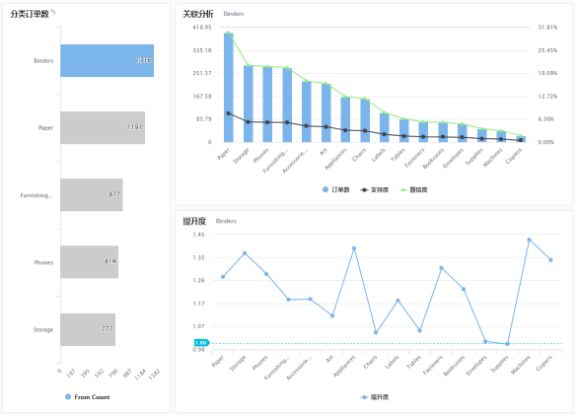
以下是利用观远数据 ETL对一家超市一年的订单商品进行了订单量的统计以及订单占比排序。
03
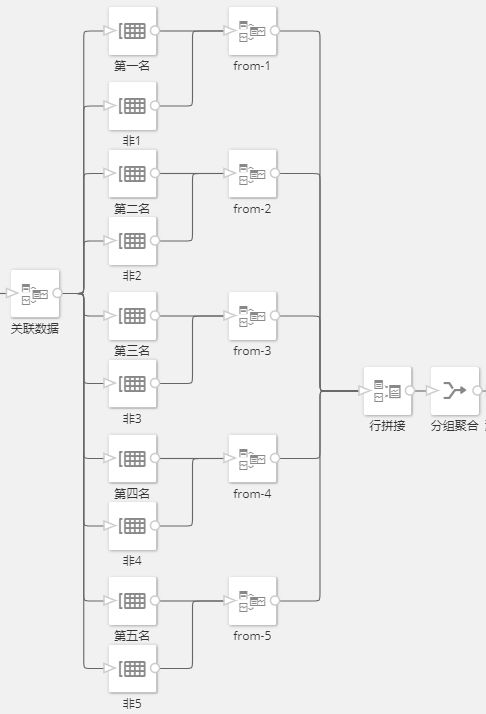
挑选出Top N商品分别与其他商品关联
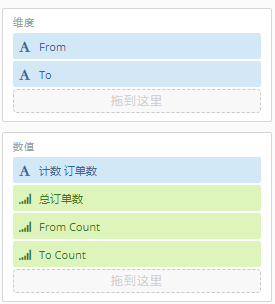
这边我们挑选了商家最为关注的Top 5商品分别与其他商品进行关联,最后聚合出以下一张关联表:
其中From为商家最为关注的Top N商品;To为与之进行关联分析的其他商品;订单数为既包含From商品,又包含To商品的订单数;From Count为包含From商品的订单数;To Count为包含To商品的订单数;总订单数则是计算时间周期内的总订单数量。
04
关联分析
前面都是一些数据的预处理,而这一步就是至关重要的关联性分析了。
这里我们需要解释几个名词:
支持度(support)
支持度:{X, Y}同时出现的概率。
例如:{尿布,啤酒}同时出现的概率
Support(X→Y) = P(X,Y) / P(I)
置信度(confidence)
置信度:购买X的人,同时购买Y的概率。
例如:购买尿布的人,同时购买啤酒的概率,而这个概率就是购买尿布时购买啤酒的置信度:
Confidence(X→Y) = P(Y|X) = P(X,Y) / P(X)
提升度(lift)
提升度:购买X的人,同时购买了Y的概率与Y总体发生概率之比。
例如:购买尿布的人,同时购买啤酒的概率与购买啤酒的整体概率之比。
Lift(X→Y)
= P(Y|X) / P(Y)= P(X,Y) /(P(X)P(Y))
若提升度Lift(X→Y) =1,表示X与Y相互独立,即是否有X,对于Y的出现无影响。虽然有可能它的支持度和置信度都非常高,但它不是一条有效的关联规则;
如果Lift(X→Y)>1,则规则“X→Y”是正关联规则,商业逻辑上X与Y是互补的;
如果Lift(X→Y) <1,则规则“X→Y”是负关联规则,商业逻辑上X与Y是互斥的。
有了这些概念,我们就可以去分析每一组关联产品之间它们的关联度到底如何了。
首先,关联度高的组合,肯定要满足一定的最小支持度与最小置信度的阈值,这个阈值可以根据情况来自行设置。
那么,是否支持度与关联度高的组合,就一定具有强关联性吗?也未必,比如商品A和商品B都是热销商品,不管商家把它们放在哪里,大家都要买,那么它们之间的支持度与置信度肯定很高,但特意把它们放在一起其实对销量的提升没有多少帮助。所以,接下去就要看提升度了。提升度≤1的组合,商品之间是相互独立或者互斥的关系,可以直接排除。我们需要在支持度与置信度符合一定要求的组合连找到提升度最高的那几个做进一步的分析。
05
数据展示
通过观远数据的可视化展示以及图表联动,我们可以清楚地看到Top 5商品与其他每一种商品之间的支持度、置信度以及提升度关系:
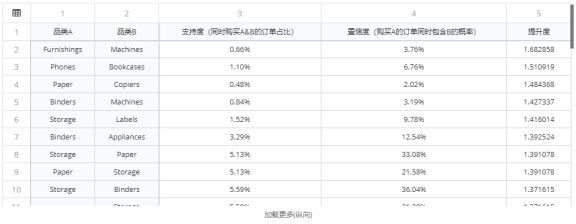
同时,我们也可以对数据进行相关的排序和筛选,找出相关性最大的关联产品,接着就可以分析这种情况出现的原因,做出相应的商品陈列调整:
这里再补充一点,在实际应用中提升度这个指标受零事务的影响较大(零事务是指既不包含From产品,也不包含To产品的事务),因此关于关联度常用的判断方法,除了提升度,还有KULC度量和不平衡比(IR)。它们可以有效的降低零事务造成的影响。
KULC=0.5*P(B|A)+0.5*P(A|B)
该公式表示 将两种事件作为条件的置信度的均值,避开了支持度的计算,因此不会受零和事务的影响。
IR=P(B|A)/P(A|B)
如果IR远远大于1,则这说明这两个事务的关联关系非常不平衡,购买商品A的顾客很可能同时会买商品B,而购买了商品B的用户不太会再去买商品A。
好了,小刚这么一讲,是不是觉得啤酒与尿布的传说也不是那么遥远了?赶紧来观远数据试试呗!
观远数据| 观点精选
【行业资讯】记一次愉快的黑客松之旅
【可视化数据】图表用得妙,年终好汇报
【数据处理系列】年度账单原来是这样产生的!
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

