
观点 | 观远首席架构师分享「从开源使用者到Apache PPMC之路」

《观点》栏目是由观远数据倾力打造的一档技术类干货分享专栏,所有内容均来源于观远数据内部员工,旨在为数据分析行业输出指导性的知识体系。
近日, 观远数据联合创始人&首席架构师吴宝琪, 作为Apache DolphinScheduler 的PPMC(项目管理委员会)成员参加了Apache DolphinScheduler 的首届用户大会, 并在大会上做了《从开源使用者到Apache PPMC之路》的分享。

Apache软件基金会创建于1999年,是专门为支持开源软件项目而创办的一个非营利性组织,也是世界上最大的开源软件基金会。而DolphinScheduler是该基金会在2019年正式孵化的项目。
作为观远数据首席架构师,吴宝琪对于分布式高可用架构的搭建有非常丰富的落地经验。此次加入DolphinScheduler项目,也将基于在观远数据技术架构搭建的经验,和更多开源开发者一起来打造一个更好用的分布式易扩展的可视化 DAG 工作流任务调度系统,解决数据处理流程中错综复杂的依赖关系,展现强大的可视化操作界面。未来,他也会把在该项目中沉淀的经验反哺到观远数据的技术架构优化中。

以下是他作为本次分享嘉宾演讲的干货整理:
Table Of Contents
1.缘起
1.1.Airflow本身是非常强大的, 我们也做了大量的Operator扩展
1.2.Apache NiFi 和 StreamSets Data Collector (简称 SDC)
1.3. Kettle 和 Talend DI
1.4. 开始调研各种开源调度项目, 并最终选定 DolphinScheduler
2.开工
2.1. 在项目中做的贡献
2.2. 简单谈谈为什么贡献开源
2.3. 开源的收获
3.未来
3.1. 打算探索的一些功能
Part 1. 缘起
观远数据是一家“AI+BI”的数据科技公司。比如: 对于BI(Business Intelligence, 商业智能)来说, 并不简单的是酷炫的可视化, 而是会涉及到大量的外部系统对接和数据融合, 这里都会牵扯到复杂的数据清洗和任务调度。虽然我们的BI中也内置了轻量的数据处理模块, 但是, 对于更复杂的任务调度/补数据等需求, 以及AI产品中的一些数据清洗/特征工程/调度等, 我们也在寻找更适合的开源工具.
1.1 阶段1, Airflow本身是非常强大的, 我们也做了大量的Operator扩展
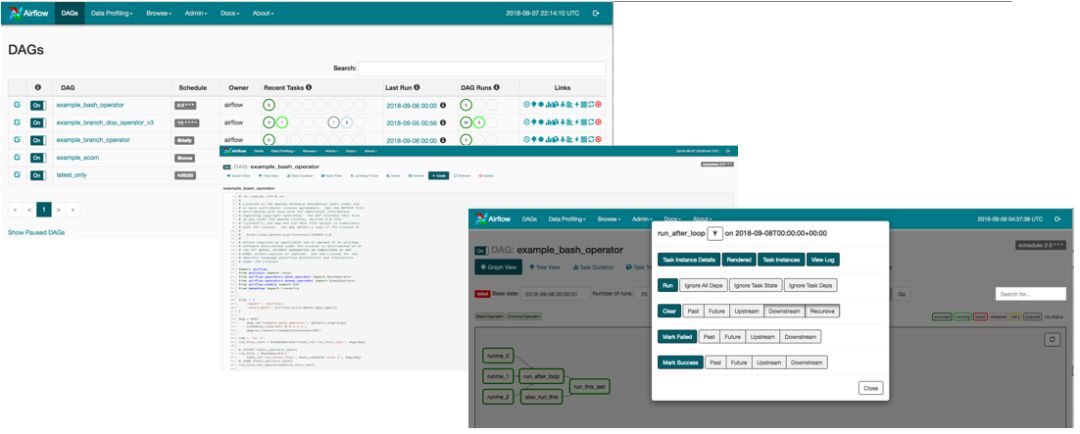
不过Airflow有个主要问题: "太依赖于Python编程, 需要做大量的Python扩展, 任务的依赖编排都要通过写Python实现"。
而我们对于调度工具的主要定位是: 需要顾问同事也能实施。对于不会编程序的顾问同事来说, 要求每个人都写Python太难了,所以我们得出的结论: 需要一个有不错的可视化界面的Web工具, 不能假设用户都会编程序。
1.2 阶段2, Apache NiFi 和 StreamSets Data Collector (简称 SDC)
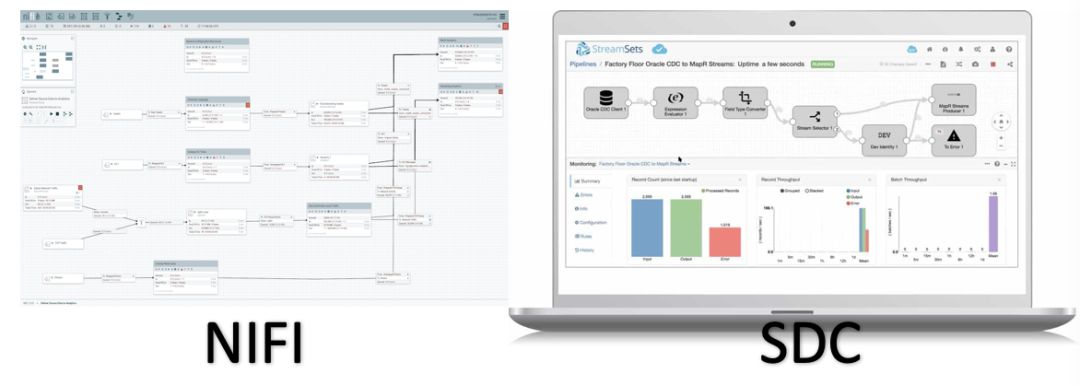
主要结论:
Nifi支持非结构化数据, 功能也比SDC多
但是: StreamSets SDC 更易用, 更好看! (更好看也是很重要的), 尤其是如下三点:
1.实时Metrics支持 (实时看到pipeline的运行信息, 而且是可视化的图形展示)。
2.代码写的很赞!
3.插件化设计赞!编写自定义插件更容易!
虽然SDC很吸引人, 不过SDC主要场景还是实时数据抽取转化. BI仍是离线定时任务为主, 所以不是完全匹配。
1.3 阶段2.5, Kettle 和 Talend DI
主要结论:
这两个都是传统的ETL, 调度功能都偏弱 (注: Talend DI是评估的开源版本, 商业版本有更复杂的调度能力, 但是价格不菲)。
插件扩展都有点复杂。
Talend 可以把job翻译成 Java工程, 赞! (这样不用每台机器都安装 Talend, 可以直接跑Jar包程序, 不过也有问题, 比如: 很多报错都是java的exception, 很多自定义扩展都需要使用者会基本的Java)。
但是这两个项目的代码都十分复杂, 阅读/掌握代码基本上太难, 而对于是否使用一个开源项目的一个很重要的考量指标是: 是否自己公司的同事能掌握这个项目。
1.4 阶段3, 开始调研各种开源调度项目, 并最终选定 DolphinScheduler

主要结论: DolphinScheduler (加入Apache前叫 EasyScheduler) 更适合我们的场景,主要原因:
Apache License
Process/Task的definition 和 instance 分离, 支持补数据, 概念清晰. 路走对了, 就不怕远
有还不错的图形化配置界面, 而不是什么都要写json配置, 或者python设置DAG等.
基于JVM, 以后方便Java Shop来扩展
Part 2. 开工
作为公司的首席架构师, 一部分的工作是思考和尝试一些公司的未来方向, 所以, 开始对于DolphinScheduler的贡献公司内部主要是我一个人奋斗 (当然我不是一个人, 我是和开源社区的很多很多小伙伴们一起奋斗), 不过现在公司内部也有其他伙伴在和我一起为开源做贡献。
2.1 在项目中做的贡献
主要的方式是: 从简单到复杂, 逐步融入社区
最开始:
熟悉项目代码, 搭建本地环境
修复一些小bug
然后可以做一些简单的功能:
增加 Clickhouse 支持
增加 Oracle 支持
增加 SQL Server支持
接下来就可以做一些更复杂些的功能了:
SQL任务增加 Pre/Post Statement支持
支持Minio/S3 作为”资源中心”的文件存储
支持CombinedServer: 多个Server一起启动, 方便本地开发
用 Sifting Appender 解决 task 日志错乱问题
当然, 贡献不是光指合并的pull request,而还包括:
Pull Request Review
社区回答问题
也包括: 来 User Meeting 分享, 宣传DolphinScheduler等 :)
2.2 简单谈谈为什么贡献开源
为开源做贡献也是一个必然的选择, 我之前在前公司就遇到过这么一个项目,开始一切都很美好,
我们基于某个开源软件, 实现了一个功能,在上面做了大量的扩展,大量的修改。直到某一天, PM过来说:这个软件已经由 1.x 升级到了 2.0,这个 2.0 做了大量的代码重构, 性能大幅提升,支持新的国际标准, 有很多新的script功能,咱们来升级支持一下吧!
结果, 负责升级的同事升级了6个月。他每天做的工作就是如下三件事:
编译C++到各个平台, 修复各种build error
仔细学习《Modern C++ Design》 这本书来了解各种特殊的C++ template写法和模式
在版本控制软件中, 查看和了解每个commit的原因/修改, 然后试着应用到新的版本上
后来, 我们反思, 除了C++和跨平台编译等原因外, 另一个重要结论就是: 对于使用的开源软件, 一定要想方设法把扩展/bugfix 合并到官方repository中, 这样长期来看会大大减少维护成本。
2.3 开源的收获
开源软件发展到今天,已经不再只是极客的个人项目为主了。开源这十年发展太快了, 开源是未来的趋势,开源和商业本身并不矛盾, 开源只是商业的一种形式,代码只是开源的一小部分, 更重要的其实是围绕这个开源项目的社区,为开源做贡献。
开源不仅能获得到apache邮箱, 也能同时收获这些:
提高代码质量, 写更多注释 (心里想着, 我写的代码, 将来要被成千上万人围观)
方案需要更通用
志同道合的朋友们
更多的使用者, 更快发现问题
对于公司来说, 也更利于公司吸引人才
Part 3. 未来
3.1 打算探索的一些功能
插件化
类似于Airflow的Pool功能, 限制同时执行的指定任务个数
工作流调度增加基于 时间触发, 复杂规则, webhook触发等机制
Task Metrics支持, 实时查看每个组件的一些metrics (比如: 输入记录数, 输出记录数, 执行时间. 以及近30次运行的变化曲线等)
工作流定义, 资源文件 等的 简单多版本管理,(查看历史, 回滚到指定版本)
数据血缘关系(data lineage)上报组件
我心中的DolphinScheduler (不负责任瞎想)未来架构, 当然, 这个只是一个设想, DolphinScheduler目前架构不是如此, 未来也不会完全一样, 只是个人的一种对于通用数据调度平台的想法。
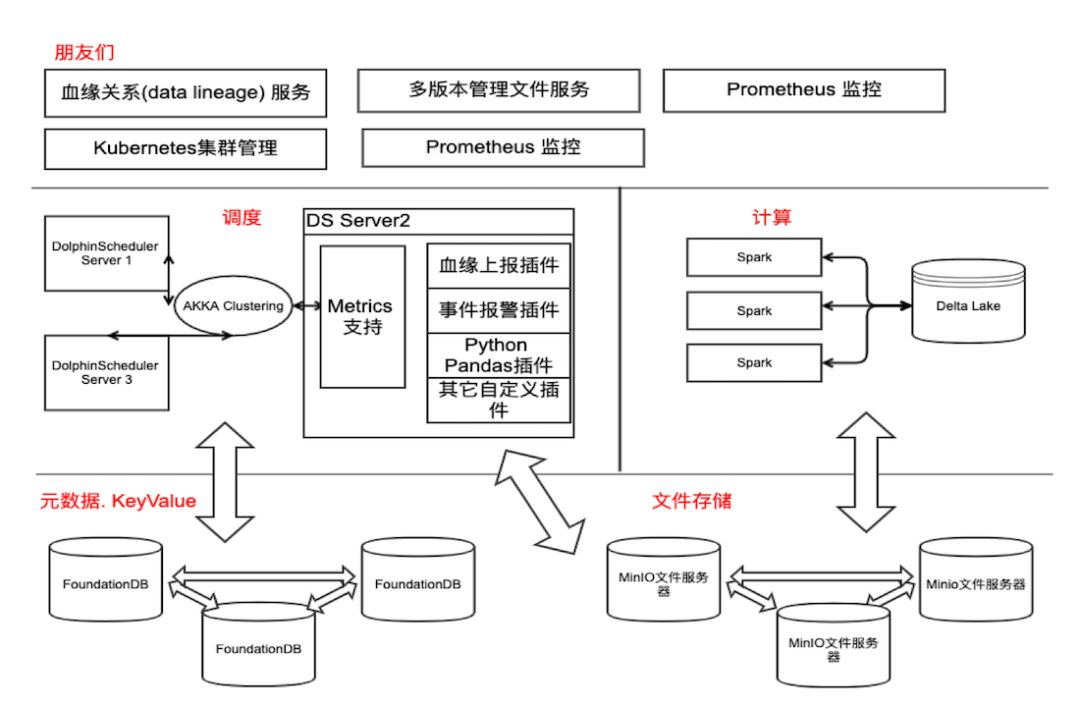
以上是我对于参与DolphinScheduler开源项目的经历的简单分享, 因为主要面向技术人员, 所以没有介绍太多比较虚的项目背景, 项目意义, 未来方向等内容。
下期预告
提前剧透一下, 根据文章反馈, 下期将会分享「观远怎么基于DolphinScheduler做的一些未来产品」。Stay Tuned!
猜 你 喜 欢




版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

