
观远BI为你详细介绍V9数据挖掘产品
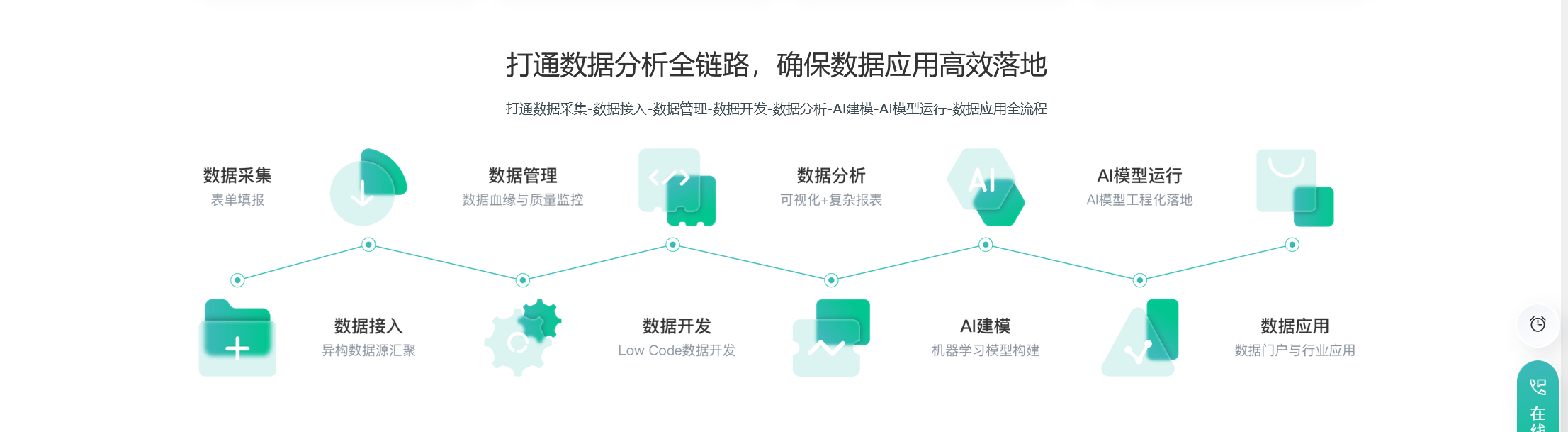
观远BI 挖矿平台是一个专注于实际生产应用的数据分析和预测平台。它旨在为个人、团队和企业做出的决策提供预测。该平台不仅为用户提供直观的流式建模、拖放操作、精简可视化的建模界面,还提供了大量的数据预处理操作。此外,它内置了多种实用经典的机器学习算法,并基于观远BI长期与企业客户的合作经验,提供了大量实用的企业级平台功能。具体特点如下:
适应大型企业
1、分布式云计算,线性伸缩,性能有保障
2、与BI平台无缝集成,挖掘模型一键发布
3、模型库提高知识复用,减少重复投资
4、支持跨库查询,统一控制数据访问权限
5、训练自动化,模型自学,提供企业级模型工厂
适合普通用户
1、直观易用的流式建模,极简的节点配置界面
2、支持可视化探索,易于理解数据质量和数据关联
3、流程节点在线帮助,按需查看
4、模型超参数自动调整,降低使用阈值
专业的算法能力
1、内置5大类机器学习成熟算法
2、支持文本分析处理
3、支持使用 Python 的扩展挖掘算法
4、支持使用 SQL 的扩展数据处理能力
5、自动特征组合,高效生成特征
从功能上看,涵盖了主流数据挖掘产品的各种功能,并有自己的特点:
01 一站式体验
业务用户无需技术层面就可以快速创建自己的工作流或模型,并将这些工作流和模型应用到实际工作中:处理后的数据可以根据观远BI分析报告等进行定制。
应用实现流程如下:
1、通过拖放自定义工作流程或模型。
2、保存工作流或模型。
3、使用观远BI报告功能自定义分析报告。
02 快速学习指南
平台内置12个代表性应用案例。初学者可以根据对案例的研究,或者通过修改案例现有工作流程的部分节点,快速掌握观远BI挖掘的使用。
03 强大的数据服务应用能力
将经过训练的模型或工作流作为服务发布,使用户能够以自助服务的方式对新数据进行预测评估或处理。
1、 支持服务部署
服务部署的作用是将训练好的优化预测模型部署为Web服务,并提供API供实际业务使用。用户可以通过调用该API直接向其发送数据,获取优化模型的预测数据。它还支持实时或批量发送数据。
根据保存的训练模型和场景案例数据(服务输入),您可以通过服务输出查看预测数据,点击部署服务自动保存到服务管理中。
2、 服务查看和删除
部署的服务可以统一管理,可以直接使用它们的API,也可以进行删除操作。如需删除,只需点击服务对应位置的删除按钮即可。
点击服务管理下服务列表中对应模型的服务,可以查看服务API的信息,也可以在程序中直接调用API获取模型预测数据,也支持修改配置信息服务的名称,如服务别名、服务描述。
在调用服务之前,可以测试服务API,确保API可以正常使用,返回的数据是否符合要求。比如输入测试数据,服务会返回测试结果。
3、 保存并应用优化后的训练模型
保留优化的训练模型是指将用户定义的模型持久化到平台,以方便后续使用。
操作入口:在“训练”节点的右键菜单中,点击保存模型,输入相关模型名称和信息:
模型将保存到训练的模型文件夹中。用户可以直接拖放训练好的模型使用,无需重新训练,但需要注意的是,使用的特征需要与训练模型时的特征保持一致。
04 多样化的数据源库和目标库支持
1、 数据源:支持读取多个数据源
观远BI挖矿平台支持五种数据源:第一是从hdfs读取的文本数据源,第二是内置案例数据源,第三是观远BI关系数据源,三是四是上传本地数据(如Excel文件)到缓存库,然后通过关系数据源读取数据,五是来自观远BI的数据集。
2、数据目标源:支持观远BI多个数据源
将实验期间的数据导出到关系数据源,如 ClickHouse、Oracle、HDFS。可供 观远BI 使用。平台除了支持将数据导出至上述关系型数据库外,还支持将数据导出至观远BI的数据库,方便用户直接将数据用于其他操作。观远BI 当前支持的数据库包括:Infobright、ClickHouse、Vertica、Oracle、Mysql、DB2、MSSQL。
05 丰富的数据预处理方法
1、 支持拆分、过滤、添加序列号等多种数据预处理方式
平台目前支持的常规预处理方法包括:随机抽样、加权抽样、分层抽样、数据拆分、字段过滤和映射、列选择、过滤空值、合并列、合并行、JOIN、元数据编辑、行选择、删除重复、排序、递增序列号、聚合、拆分列、派生列、类型转换。
2、 支持数据选择、变换、离散化、主成分特征提取等操作
平台支持数据的特殊处理:连续数据的离散化、字符数据到离散数据的转换、高维数据的降维提取主成分特征等。特征自动选择。
3、 支持自动调参
该平台支持所有算法的自动优化参数调整。
这些特殊的处理操作可以轻松帮助用户利用有效数据,帮助用户从众多数据中找到有价值的数据。
4、与 SQL 脚本语言的无缝集成
平台可支持SQL语言,满足高级分析需求,实现自定义算法的快速集成和添加。
06 大量实用的机器学习算法
平台支持多种高效实用的机器学习算法,包括分类、聚类、回归等算法,包括多种可训练模型:逻辑回归、决策树、随机森林、朴素贝叶斯、支持向量机、线性回归、K -均值、DBSCAN、高斯混合模型。
平台支持的分类预测算法:逻辑回归、朴素贝叶斯、支持向量机、决策树、随机森林。分类预测算法主要用于分类预测划分。使用场景:疾病预测、电力违约预测、类型分类、替换预测、银行金融产品订单预测、信用预测。
平台支持的回归预测算法:线性回归。回归预测法主要用于趋势预测。使用场景:天气预报、房价预测、库存预测。
平台支持的聚类算法:K-means、高斯混合模型、DBSCAN。聚类算法主要用于特征分组。使用场景:企业信息聚类、酒类识别。
这些经典算法高效易用,可以满足用户不同的使用场景,帮助客户轻松实现数据挖掘。
07 灵活的扩展接口
支持自定义Python或JAVA代码,灵活帮助用户扩展算法库和资源树节点。
08 可视化
平台的可视化效果主要包括:工作流定制可视化、数据可视化、分析结果可视化。
1、工作流程自定义可视化:拖放节点和连接,直观的流程建模
2、数据可视化:数据预处理结果的可视化,通常以表格形式
3、分析结果可视化:支持相关分析、平行坐标、散点图等统计分析和图表
09 完善的备份机制
为避免数据意外损坏,观远BI挖矿平台和观远BI系统均支持资源备份,用户可根据自身需求选择合适的方式。
1、工作流导出导入
工作流备份是指将工作流DAG资源单独导出到本地,文件后缀名为“.观远BIm”。
2、资源导出和导入
平台支持一个或多个案例资源的导入导出。资源导入是指将本地案例资源导入系统知识库。该功能与资源导出配合使用,常用于开发机和生产机系统之间资源文件的迁移。平台支持将一个或多个案例资源从本地导入系统。此外,平台还可以从系统中导出资源,即将系统知识库中的案例资源以“.xml”格式导出到本地。导出案例资源时,导出的案例资源将包括其名称、描述信息和参数信息。
3、知识库备份与恢复
知识库备份是指知识库中的所有资源文件都以“.zip”格式存储在本地。
知识库备份可用于知识库迁移。定期备份知识库可以帮助用户保护他们的数据不被意外丢失。
备份知识库通过恢复操作实现知识库数据的恢复。


